I have the following CSV:
COLUMN_A;COLUMN_B;COLUMN_C;COLUMN_D;COLUMN_E;COLUMN_F;COLUMN_G;COLUMN_H;COLUMN_I;COLUMN_L;
01234;AB ;00001; ;100000001; ;ABC; 0000000000099998,080;XYZ ;
I would like to remove the white spaces only if the value is not blank. So the result will be like this:
COLUMN_A;COLUMN_B;COLUMN_C;COLUMN_D;COLUMN_E;COLUMN_F;COLUMN_G;COLUMN_H;COLUMN_I;COLUMN_L;
01234;AB;00001; ;100000001; ;ABC; 0000000000099998,080;XYZ;
I know that I can use find ' ' replace '' so the space will be replaced by nothing. But in this way, I will remove all the spaces, and I want to maintain the string with spaces where there aren't any other character.
If I have to use regular expression (my first time), I think I need to concatenate the following expression:
[a-zA-Z]
[\s]
[;]
so I can use [a-zA-Z][\s][;] in the find box,
but I don't know how to replace what it finds with [a-zA-Z][;]
CodePudding user response:
You can distinguish the cases where the string of spaces is not prefixed with a semi-colon or white-space, and the cases where the string of spaces is not suffixed with a semi-colon or white-space.
For this you can use look-around:
Find what: \h (?![;\s])|(?<![;\s])\h
Replace with: (empty)
⦿ Regular expression
Replace all
Explanation
\hmatches a horizontal white-space character (so not newline)(?![;\s])is a negative look ahead: what follows at the current position should not be one of those characters, but they are not included in the overall match.(?<![;\s])is a negative look behind: what precedes at the current position should not be one of those characters, but they are not included in the overall match.
CodePudding user response:
- Ctrl H
- Find what:
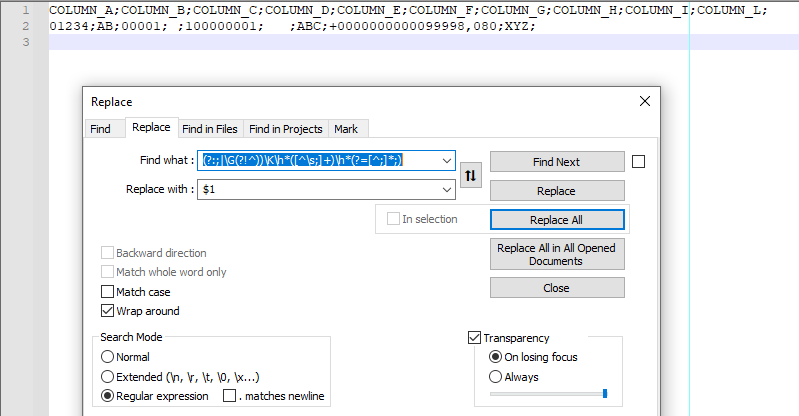
(?:;|\G(?!^))\K\h*([^\s;] )\h*(?=[^;]*;) - Replace with:
$1 - TICK Wrap around
- SELECT Regular expression
- Replace all
Explanation:
(?: # non capture group
; # semi-colon
| # OR
\G # restart from last match position
(?!^) # not the beginning of line
) # end group
\K # forget all we have seen until this position
\h* # 0 or more horizontal spaces
( # group 1
[^\s;] # 1 or more any character that is not a space or semi-colon
) # end group
\h* # 0 or more horizontal spaces
(?= # positive lookahead, make sure we have after:
[^;]* # 0 or more any character that is not a semi-colon
; # a semi-colon
) # end lookahead
Screenshot (before):
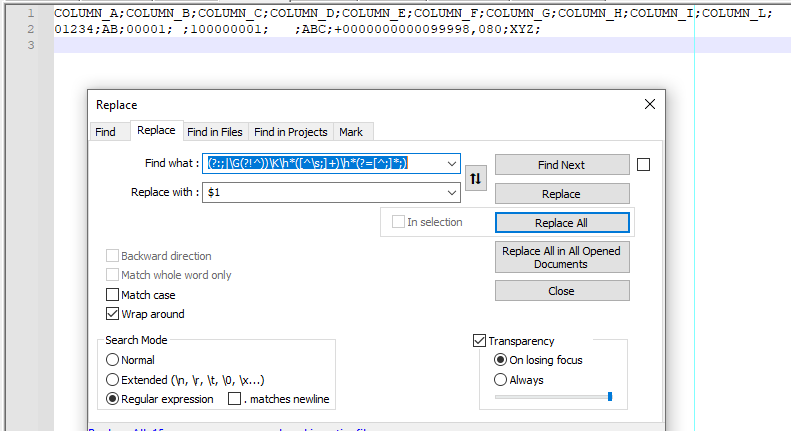
Screenshot (after):
CodePudding user response:
To answer my last question,
It is possible to capture a group by surrounding it with parentheses (round brackets) and each one will be numerated starting from 1, so it will be possible to use them by prefixing the number with a dollar.
In the find box:
([a-zA-Z])([ ]{1,})([;])
in the replace box
$1$3