I'm trying to highlight duplicate rows in several dataframes and export them to excel after. It seems to work when I do it with one dataframe, but as soon as I apply it to another dataframe is highlights the index from the last dataframe for all of them.
Here is my code:
import pandas as pd
import numpy as np
colA = list(range(1,6))
colB = ['aa', 'bb', 'aa', 'cc', 'aa']
colC = [14,3,14,9,12]
colD = [108, 2001, 152, 696, 696]
df = pd.DataFrame(list(zip(colA, colB, colC, colD)), columns =['colA', 'colB', 'colC', 'colD'])
print(df)
colA = list(range(1,7))
colB = [208, np.nan ,201, 150, 900, 670]
colC = ['aa', np.nan ,'bb', 'aa', 'cc', 'bb']
df2 = pd.DataFrame(list(zip(colA, colB, colC)), columns =['colA', 'colB', 'colC'])
print(df2)
def highlight_yellow(x):
return ['background-color: yellow' if x.name in rows else '' for i in x]
row_series = df['colB'].dropna(how = 'any').duplicated(keep = False)
rows = row_series[row_series].index.values
df = df.style.apply(highlight_yellow, axis = 1)
row_series = df2['colC'].dropna(how = 'any').duplicated(keep = False)
rows = row_series[row_series].index.values
df2 = df2.style.apply(highlight_yellow, axis = 1)
When I just run the highlight function on the first dataframe it produces the correct results
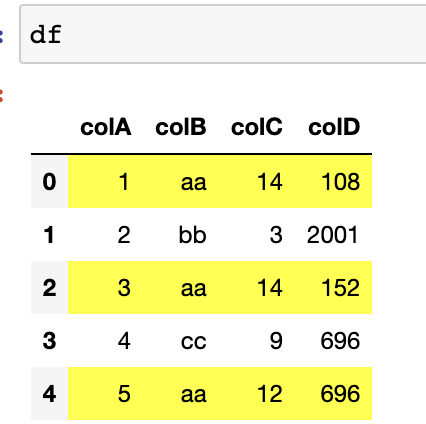
But when I run it on both dataframes it overrides the correct result in the first dataframe, and highlights the same rows in the first and second dataframe instead.
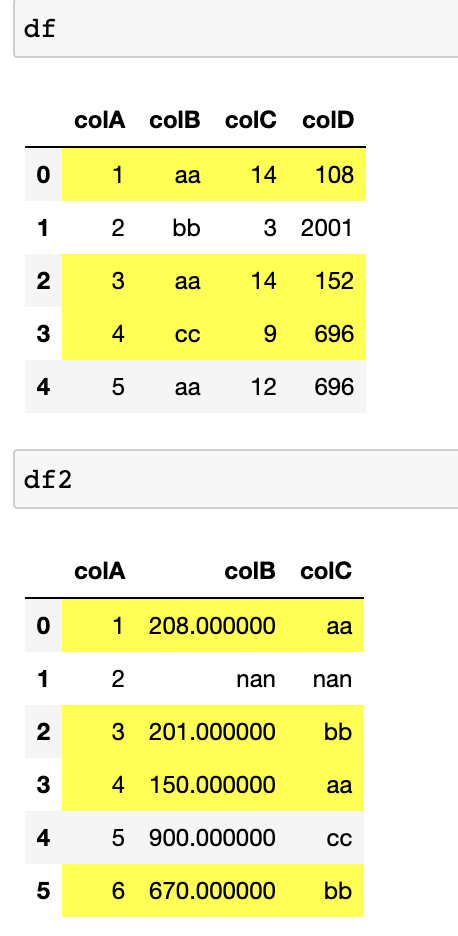
The end result should look like this:
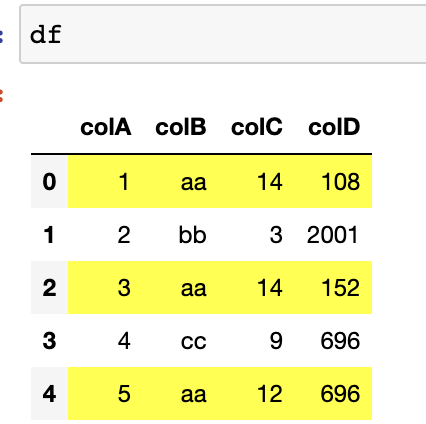
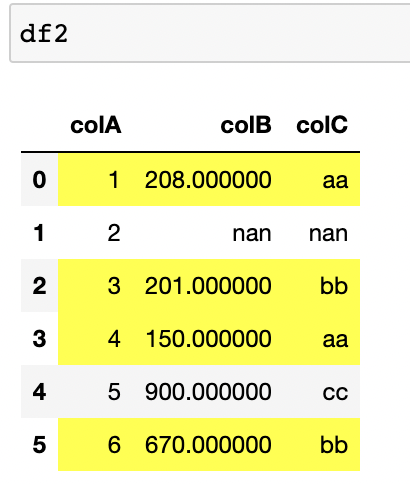
CodePudding user response:
You can use:
def highlight_yellow(df, cols):
style = 'background-color: yellow'
a = np.broadcast_to(np.where(df.duplicated(subset=cols), style, '')[:,None], df.shape)
return pd.DataFrame(a, index=df.index, columns=df.columns)
df.style.apply(highlight_yellow, cols=['colB'], axis=None)
output:
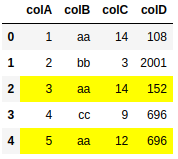
df2.style.apply(highlight_yellow, cols=['colC'], axis=None)
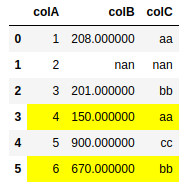
CodePudding user response:
The dropna method first removes the rows with nan which affects the rows. You should do it separately something like below:
row_series = df2['colC'].duplicated(keep = False)
row_series[df2['colC'].isna()] = False