I have a data-frame:
df = pd.DataFrame({'A': ['2022-09-09', '2022-09-12', '2022-09-12', '2022-09-12', '2022-09-13'],
'B' : ['2022-09-01', '2022-09-02', '2022-09-03', '2022-09-04', '2022-09-05'],
'C' : [4701.80, 0, 12571.13, 0, 3011.06]})
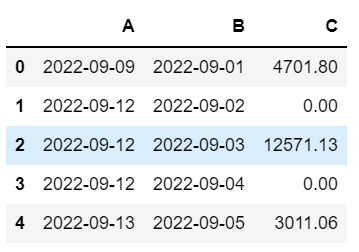
I would like to fill in 0 values with the non-0 values as per key date in column A so the result would be :
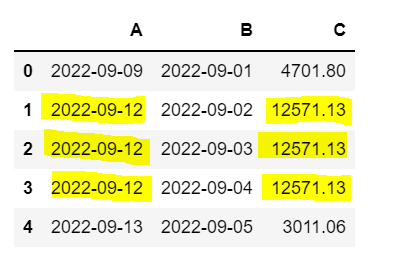 How can I do it?
How can I do it?
CodePudding user response:
IIUC, you can apply a ffill/bfill per group using groupby.apply:
df['C'] = (df['C'].mask(df['C'].eq(0))
.groupby(df['A'], group_keys=False)
.apply(lambda s: s.ffill().bfill())
)
output:
A B C
0 2022-09-09 2022-09-01 4701.80
1 2022-09-12 2022-09-02 12571.13
2 2022-09-12 2022-09-03 12571.13
3 2022-09-12 2022-09-04 12571.13
4 2022-09-13 2022-09-05 3011.06
If you have a unique non-zero value per group, an alternative would be to use groupby.transform('first'):
df['C'] = (df['C'].mask(df['C'].eq(0))
.groupby(df['A'], group_keys=False)
.transform('first')
)
CodePudding user response:
# change the zero to null, to aid in making use of [fillna][1]
df['C']=df['C'].mask(df['C'].eq(0))
#do a groupby on 'A' and then do a ffill and bfill
df['C']=df.groupby(['A'])['C'].apply(lambda x: x.fillna(method='ffill').bfill() )
df
A B C
0 2022-09-09 2022-09-01 4701.80
1 2022-09-12 2022-09-02 12571.13
2 2022-09-12 2022-09-03 12571.13
3 2022-09-12 2022-09-04 12571.13
4 2022-09-13 2022-09-05 3011.0
CodePudding user response:
One way to do it using groupby and transform,
df['C']=df.groupby('A')['C'].transform(lambda s: s[s.ne(0).idxmax()])
Full Code:
import pandas as pd
df = pd.DataFrame({'A': ['2022-09-09', '2022-09-12', '2022-09-12', '2022-09-12', '2022-09-13'],
'B' : ['2022-09-01', '2022-09-02', '2022-09-03', '2022-09-04', '2022-09-05'],
'C' : [4701.80, 0, 12571.13, 0, 3011.06]})
df['C']=df.groupby('A')['C'].transform(lambda s: s[s.ne(0).idxmax()])
print(df)
Output:
A B C
0 2022-09-09 2022-09-01 4701.80
1 2022-09-12 2022-09-02 12571.13
2 2022-09-12 2022-09-03 12571.13
3 2022-09-12 2022-09-04 12571.13
4 2022-09-13 2022-09-05 3011.06