I want to concatenate two dataframes that have the same columns and remove duplicates.
I then want to remove duplicates of the new dataframe based on multiple key columns.
For example I have these two dataframes
import pandas as pd
data1 = {'first_column': ['1', '2', '2', '2'],
'second_column': ['1', '2', '2', '2'],
'key_column1':['1', '2', '2', '6'],
'key_column2':['1', '2', '2', '1'],
'fourth_column':['1', '2', '2', '2'],
}
df1 = pd.DataFrame(data1)
data2 = {'first_column': ['1', '2', '2', '2'],
'second_column': ['1', '2', '2', '2'],
'key_column1':['1', '3', '2', '6'],
'key_column2':['1', '5', '2', '2'],
'fourth_column':['1', '2', '2', '2'],
}
df2 = pd.DataFrame(data2)
Expected output:

CodePudding user response:
Use pandas.concat to concatenate a list of dataframes. Then, use pandas.DataFrame.drop_duplicates() to drop the duplicate records. The pandas.DataFrame.drop_duplicates() function has a parameter called subset that you can use to determine which columns to include in the duplicates search. Here's how to do it, using the example you gave:
import pandas as pd
data1 = {
"first_column": ["1", "2", "2", "2"],
"second_column": ["1", "2", "2", "2"],
"key_column1": ["1", "2", "2", "6"],
"key_column2": ["1", "2", "2", "1"],
"fourth_column": ["1", "2", "2", "2"],
}
df1 = pd.DataFrame(data1)
data2 = {
"first_column": ["1", "2", "2", "2"],
"second_column": ["1", "2", "2", "2"],
"key_column1": ["1", "3", "2", "6"],
"key_column2": ["1", "5", "2", "2"],
"fourth_column": ["1", "2", "2", "2"],
}
df2 = pd.DataFrame(data2)
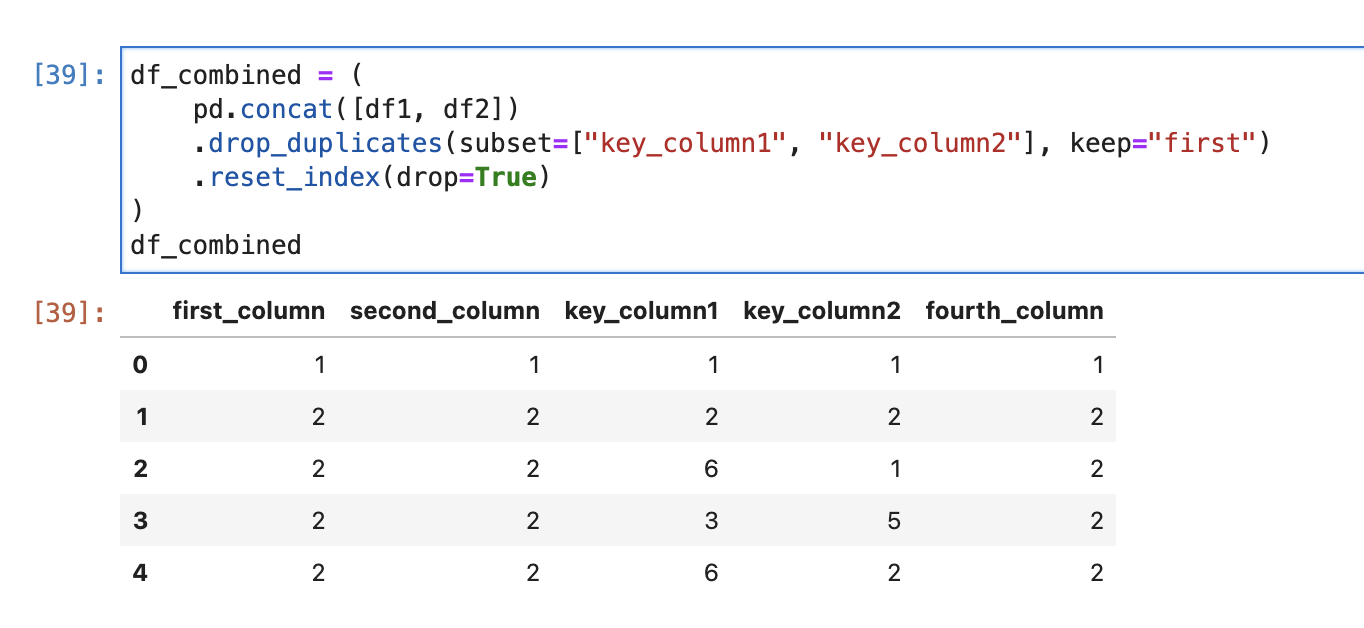
df_combined = (
pd.concat([df1, df2])
.drop_duplicates(subset=["key_column1", "key_column2"], keep="first")
.reset_index(drop=True)
)
df_combined
The above code outputs the following:
If you want to wrapt it all inside of a function here's how you might consider doing it:
from __future__ import annotations
from typing import List
import pandas as pd
def concat_no_dups(*dfs: pd.DataFrame, key_columns: List[str] | str | None = None) -> pd.DataFrame:
"""
Concatenate dataframes together and drop duplicates based on equality of
selected columns.
Parameters
----------
dfs : pd.DataFrame
A sequence of dataframes.
key_columns : List[str] | str | None, optional
The columns to use as keys to drop duplicates.
If no list, or column provided, it uses all the columns
from the concatenated dataframe, to search for duplicates
Returns
-------
df_combined : DataFrame
The concatenated dataframe with duplicate rows removed.
Raises
------
KeyError
If one or more keys from `key_columns` do not exist in the dataframe,
obtained after combining all `dfs` together.
Examples
--------
>>> import pandas as pd
>>> data1 = pd.DataFrame(
[['a', 12], ['a', 15], ['b', 19], ['c', 18]],
columns=['key', 'value']
)
>>> data2 = pd.DataFrame(
[['a', 16], ['a', 10], ['b', 13], ['e', 19]],
columns=['key', 'value']
)
>>> concat_no_dups(data1, data2, key_columns='key')
key value
0 a 12
1 b 19
2 c 18
3 e 19
>>> concat_no_dups(data1, data2, key_columns=['key', 'value'])
key value
0 a 12
1 a 15
2 b 19
3 c 18
4 a 16
5 a 10
6 b 13
7 e 19
>>> concat_no_dups(data1, data2)
key value
0 a 12
1 a 15
2 b 19
3 c 18
4 a 16
5 a 10
6 b 13
7 e 19
>>> concat_no_dups(data1, data2, data1)
key value
0 a 12
1 a 15
2 b 19
3 c 18
4 a 16
5 a 10
6 b 13
7 e 19
"""
df_combined = pd.concat([df for df in dfs])
if key_columns is None:
key_columns = list(df_combined.columns)
elif not hasattr(key_columns, '__iter__') or isinstance(key_columns, str):
key_columns = [key_columns]
missing_keys = pd.Index(key_columns).difference(df_combined.columns)
if not missing_keys.empty:
raise KeyError(
f"The following key columns weren't found: {list(missing_keys)}. "
f"Available columns: {list(df_combined.columns.astype(str))}."
)
return df_combined.drop_duplicates(subset=key_columns).reset_index(drop=True)
CodePudding user response:
You need first to concat"
df = pd.concat([df1, df2])
And then to remove duplicates by not leaving any of them (keep=False):
df.drop_duplicates(keep=False, inplace=True)
df
first_column second_column key_column1 key_column2 fourth_column
3 2 2 6 1 2
1 2 2 3 5 2
3 2 2 6 2 2
if you need to reset the index, do:
df.reset_index(drop=True, inplace=True)
df
first_column second_column key_column1 key_column2 fourth_column
0 2 2 6 1 2
1 2 2 3 5 2
2 2 2 6 2 2