I have a DataFrame as follows:
data = [[99330,12,122], [1123,1230,1287], [123,101,812739], [1143,12301230,252]]
df1 = pd.DataFrame(data, index=['2022-01-01', '2022-01-02', '2022-01-03', '2022-01-04'], columns=['col_A', 'col_B', 'col_C'])
df1 = df1/df1.shift(1)-1
df1['mean'] = df1.mean(axis=1)
df1['upper'] = df1['mean'] df1.filter(regex='col').std(axis=1)
df1:
col_A col_B col_C mean upper
2022-01-01 NaN NaN NaN NaN NaN
2022-01-02 -0.988694 101.500000 9.549180 36.686829 93.063438
2022-01-03 -0.890472 -0.917886 630.498834 209.563492 574.104192
2022-01-04 8.292683 121793.356436 -0.999690 40600.216476 110915.538448
I want to create a second DataFrame only with the values of col_A, col_B, col_C that are greater than df['upper'] and fill all other values with nan.
So the DataFrame should look like this
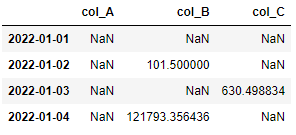
df2:
col_A col_B col_C
2022-01-01 NaN NaN NaN
2022-01-02 NaN 101.500000 NaN
2022-01-03 NaN NaN 630.498834
2022-01-04 NaN 121793.356436 NaN
Is there a way to do this Pythonically without having to go through many loops?
CodePudding user response:
Filter the "col" columns and make a vectorized greater-than comparison using gt() on axis and mask the unwanted values via where() method.
# replace the values in "col" columns that are less than df1.upper
df2 = df1.filter(like='col').where(lambda x: x.ge(df1['upper'], axis=0))
df2
CodePudding user response:
Try this... not sure if this is the best way, as I did use one for loop...
import numpy as np
data = [[99330,12,122], [1123,1230,1287], [123,101,812739], [1143,12301230,252]]
df1 = pd.DataFrame(data, index=['2022-01-01', '2022-01-02', '2022-01-03', '2022-01-04'], columns=['col_A', 'col_B', 'col_C'])
df1 = df1/df1.shift(1)-1
df1['mean'] = df1.mean(axis=1)
df1['upper'] = df1['mean'] df1.filter(regex='col').std(axis=1)
df2 = df1.copy()
for col in cols:
if "col" in col:
df2[col] = df2.apply(lambda x: x[col] if x[col] > x["upper"] else np.nan,axis=1)
df2 = df2[[col for col in df1.columns if "col" in col]]
# Output...
col_A col_B col_C
2022-01-01 NaN NaN NaN
2022-01-02 NaN 101.500000 NaN
2022-01-03 NaN NaN 630.498834
2022-01-04 NaN 121793.356436 NaN
CodePudding user response:
You can use lambda functions to achieve this
import numpy as np
df2 = pd.DataFrame(data, index=['2022-01-01', '2022-01-02', '2022-01-03', '2022-01-04'], columns=['col_A', 'col_B', 'col_C'])
df2['col_A'] = df1.apply(lambda x: x.col_A if x.col_A > x.upper else np.nan, axis=1)
df2['col_B'] = df1.apply(lambda x: x.col_B if x.col_B > x.upper else np.nan, axis=1)
df2['col_C'] = df1.apply(lambda x: x.col_C if x.col_C > x.upper else np.nan, axis=1)