Need help counting the occurrence that values in two columns are greater than a value in the same row. For example, if I want to count the number of times each row is greater than 4 and I have columns X & Y such that:
X Y
2 1
5 5
6 3
5 5
The output variable will be 2 since both numbers are greater than 4 in two rows, row 2 and 4.
Thank you
CodePudding user response:
In [134]: df.gt(4).all(axis="columns").sum()
Out[134]: 2
- check if values are greater than 4; gives True/False's (frame)
- check if we have all True's per row; gives True/False's again (series)
- sum to get the count as True -> 1, False -> 0
CodePudding user response:
What about a comparison like this, in case you're not looking to use any additional packages.
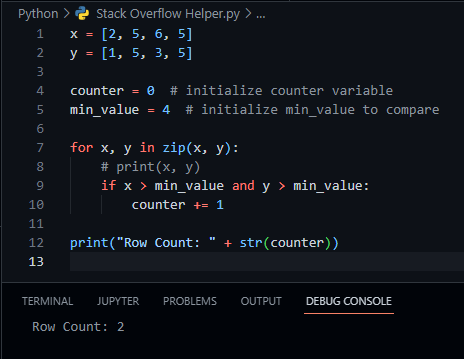
x = [2, 5, 6, 5]
y = [1, 5, 3, 5]
counter = 0 # initialize counter variable
min_value = 4 # initialize min_value to compare
for x, y in zip(x, y):
# print(x, y)
if x > min_value and y > min_value:
counter = 1
print("Row Count: " str(counter))