Situation:
- I have a program which generates 600 random numbers per "step".
- These 600 numbers are fed into a complicated algorithm, which then outputs a single value (which can be positive or negative) for that "step"; let's call this Value-X for that step.
- This Value-X is then added to a Global-Value-Y, making the latter a running sum of each step in the series.
- I have essentially run this simulation 1,000,000 times, recording the values of Global-Value-Y at each step in those simulations.
- I have "calculated confidence intervals" from those one-million simulations, by sorting the simulations by (the absolute value of) their Global-Value-Y at each column, and finding the 90th percentile, the 99th percentile, etc.
What I want to do:
- Using the pool of simulation results, "extrapolate" from that to find some equation that will estimate the confidence intervals for results from the used algorithm, many "steps" into the future, without having to extend the runs of those one-million simulations further. (it would take too long to keep running those one-million simulations indefinitely)
Note that the results do not have to be terribly precise at this point; the results are mainly used atm as a visual indicator on the graph, for the user to get an idea of how "normal" the current simulation's results are relative to the confidence-intervals extrapolated from the historical data of the one-million simulations.
Anyway, I've already made some attempts at finding an "estimated curve-fit" of the confidence-intervals from the historical data (ie. those based on the one-million simulations), but the results are not quite precise enough.
Here are the key parts from the curve-fitting Python code I've tried: (link to 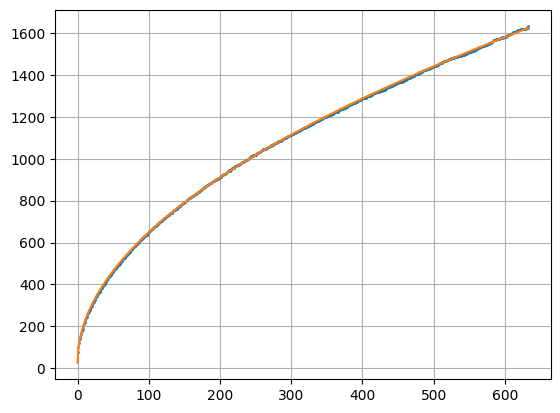
Of course this is just an adjustment to an arbitrary model chosen based on a personal experience (to me it looks like a specific heterogeneous reaction kinetics).
If you have a theoretical reason to accept or reject this model then you should use it to discriminate. I would also investigate units of parameters to check if they have significant meanings.
But in any case this is out of scope of the Stack Overflow community which is oriented to solve programming issues not scientific validation of models (see Cross Validated or Math Overflow if you want to dig deeper). If you do so, draw my attention on it, I would be glad to follow this question in details.