I have an Age category column in my pandas dataframe, df. In the Age category column, there are 32% missing values which I need to do some imputation. I'm thinking to use the distribution of the available data, which is 68% to impute the missing values.
The screenshot below is the distribution of the available data (the 68%) for the age category:
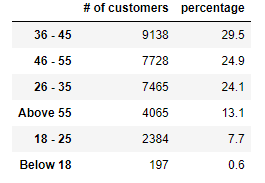
As you can see from the table,
36 - 45, having 29.5%46 - 55, having24.9%- etc..
Hence, I will expect that when I'm doing the imputation for the 32% missing values, age 36 - 45 will have approximately 29.5% as well, age 46 - 55 will have approximately 24.9% and etc...
Once I impute all the NaN in the Age category column, the overall distribution should not vary a lot compare to the one in the screenshot. May I know how should I achieve that?
Any help or advice will be greatly appreciated!
CodePudding user response:
I would procede as follow
Given your grouped df (I renamed the groups from 0 to n for simplicity):
import pandas as pd
import numpy as np
df = pd.DataFrame({'group':list(range(6)),
'percentage':[29.5,24.9,24.1,13.1,7.7,0.6]})
And a second df2 containing all rows with missing Ages:
df2 = pd.DataFrame({'person':list(range(100))})
First create a list of your percentage threshold and get a cumulative sum of percentage:
list1 = df.percentage.tolist()
cumlist = np.cumsum(list1)
To properly categorize, you have to insert the lower bound and manually set the upper one to 100 (in case the list of rounded percentage doesn't sum up to 100). Note that with this rearrangement all the missing percentage points will be added to the last group (in your case Below 18)
cumlist1 = [0.0,*cumlist[:-1],100]
Then you have to label each row of df2 with a random value from 0 to 100 and categorize it with pandas.cut()
df2['random'] = np.random.random_sample(len(df2))*100
df2['category'] = pd.cut(df2['random'],cumlist1, include_lowest=True,
labels=df['group'].tolist())