I have written a small program, it is working, but it is adding argument value into column which I do not need.
Input:
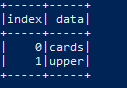
Expected:
Image above one upper into upper case
Getting:
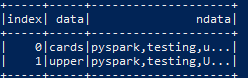
Code:
#!/usr/bin/env python
import sys
import logging
from pyspark.sql.types import StringType
from pyspark.sql import SparkSession
from pyspark.sql.functions import udf, lit
from functools import partial
def main():
process_function = {'TOLOWER' : process_lower_function }
spark = SparkSession.builder.master("local[1]").appName('intelligent').getOrCreate()
data = [(0, "cards"), (1, "upper")]
deptColumns = ["index", "data"]
df = spark.createDataFrame(data=data, schema = deptColumns)
print (df.show())
process_rule = "pyspark,testing,upper"
lower_function = partial(process_lower_function, process_rule)
udf_parser = udf(lower_function)
df = df.withColumn("ndata",udf_parser("data"))
#df.write.csv("udf.csv")
print (df.show())
def process_lower_function(text, lower_rule):
print (lower_rule)
for rule in lower_rule.split(","):
if rule in text:
text = text.replace(rule, rule.upper())
logging.info(f"LOWER :: {text} -- {rule}")
print (text)
return text
if __name__ == "__main__":
sys.exit(main())
CodePudding user response:
In this definition...
lower_function = partial(process_lower_function, process_rule)
... since you did not tell which process_lower_function function's argument should process_rule be used for, it is using the first one, i.e. text. But it seems you wanted process_rule to be used for the argument lower_rule. In this case you should use
lower_function = partial(process_lower_function, lower_rule=process_rule)
Also, if you don't want a new column, replace the existent column's values. Instead of
df = df.withColumn("ndata",udf_parser("data"))
use
df = df.withColumn("data", udf_parser("data"))
The following seems to be working to me.
import logging
from functools import partial
from pyspark.sql import functions as F
def process_lower_function(text, lower_rule):
print (lower_rule)
for rule in lower_rule.split(","):
if rule in text:
text = text.replace(rule, rule.upper())
logging.info(f"LOWER :: {text} -- {rule}")
print(text)
return text
data = [(0, "cards"), (1, "upper")]
deptColumns = ["index", "data"]
df = spark.createDataFrame(data=data, schema=deptColumns)
df.show()
# ----- -----
# |index| data|
# ----- -----
# | 0|cards|
# | 1|upper|
# ----- -----
process_rule = "pyspark,testing,upper"
lower_function = partial(process_lower_function, lower_rule=process_rule)
udf_parser = F.udf(lower_function)
df = df.withColumn("data", udf_parser("data"))
df.show()
# ----- -----
# |index| data|
# ----- -----
# | 0|cards|
# | 1|UPPER|
# ----- -----
On the other hand, you should try to find better methods than udf. The best would be native Spark functions. If not that, then pandas_udf - it is vectorized for performance, while simple udf runs slowly.
I was not able to think of a native Spark solution, but the following pandas_udf should do what you want.
Input:
from pyspark.sql import functions as F
import pandas as pd
import re
data = [(0, "cards"), (1, "uppers_testings")]
deptColumns = ["index", "data"]
df = spark.createDataFrame(data=data, schema=deptColumns)
df.show()
# ----- ---------------
# |index| data|
# ----- ---------------
# | 0| cards|
# | 1|uppers_testings|
# ----- ---------------
Script:
@F.pandas_udf("string")
def to_upper(col: pd.Series) -> pd.Series:
def repl(s):
process_rule = "pyspark|testing|upper"
return re.sub(fr'(.*?)({process_rule}|$)', lambda m: m.groups()[0] m.groups()[1].upper(), s)
return col.apply(repl)
df.withColumn("data", to_upper("data")).show()
# ----- ---------------
# |index| data|
# ----- ---------------
# | 0| cards|
# | 1|UPPERs_TESTINGs|
# ----- ---------------