I'm working with a csv file from a customer, which holds a large amount of data. The data is extracted from an SQL database and the commas therefore signify the different columns. In one of these columns there are 10 digit numbers. For some reason all 10 digit numbers starting with 0 have been converted to 9 digit numbers with the 0 removed. I need to find all these instances and insert a 0 at the beginning of the 9 digit number.
A complication in the data is that another column also contains 9 digit numbers, and these do not need to be modified. I can assume, however that all those numbers start with 0 and all the numbers i need to find do not start with 0.
I'm currently using notepad trying to fix the problem and found the regular expression \d{9} which finds all numbers with 9 digits, but that is not what I'm looking for
Below i have an example of how the data could look. The column that needs all 9 digit numbers converted is on the left, and the other column with 9 digit numbers is on the right. An example of the data that is causing the trouble could be:
| Column 1 | Column 2 |
|---|---|
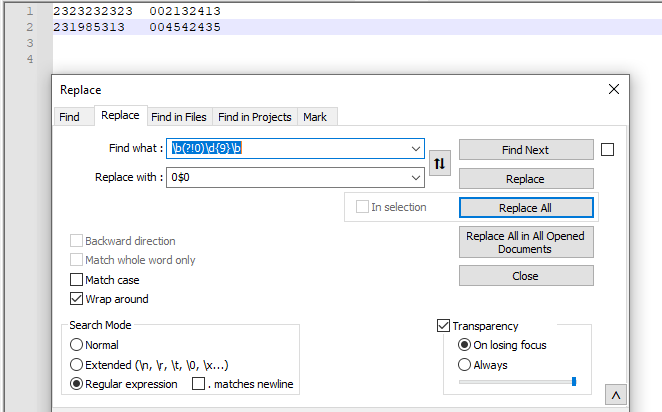
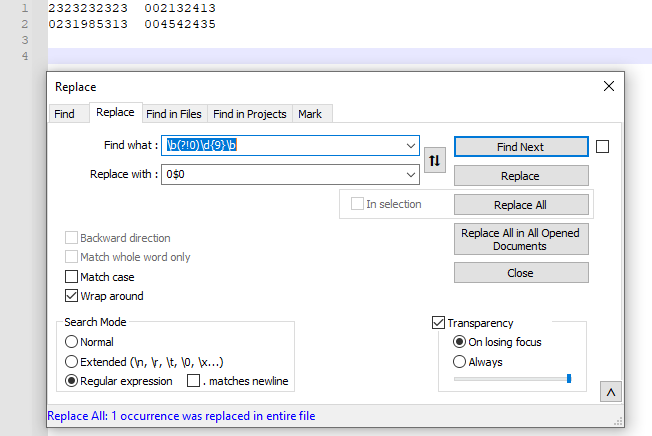
| 2323232323 | 002132413 |
| 231985313 | 004542435 |
In this example I need to find the second line of column 1 and insert a 0 in front of the number.
CodePudding user response:
- Ctrl H
- Find what:
\b(?!0)\d{9}\b - Replace with:
0$0 - TICK Wrap around
- SELECT Regular expression
- Replace all
Explanation:
\b # word boundary, make sure ae haven't digit before
(?!0) # negative lookahead, make sure the next character is not 0
\d{9} # 9 digits
\b # word boundary, make sure ae haven't digit after
Replacement:
0 # 0 to be inserted
$0 # the whole match (i.e. 9 digts)
Screenshot (before):
Screenshot (after):
CodePudding user response:
Using Notepad do CTRL H (search and replace utility).
- Tick
Regular Expression - Find what ?
([^0-9])(\d{9})([^0-9]) - Replace with ?
\10\2\3
Explanation :
([^0-9])(\d{9})([^0-9]) matches a 9 digit number surrounded by a non-digit on each side (including line return / comma, etc) :
- Each
(....)"captures" a group for later use (in "replace"). [^0-9]is a non-number character\d{9}is a 9 digits number
\10\2\3 is a 0 right after the first captured group \1 (it was just one character here) followed by the 9 digit number (2nd captured group : \2) and the character that was after that number (3rd captured group : \3).
Limit :
It won't match a number at the very beginning of the file (before any other character) or at the very end (after every character). Adding a newline at the end of the file is one workaround, or fixing the last number manually if there is no newline before EOF.