Looking to Pass Python a list then using a combinate of Beautiful soup and requests, pull the corresponding peice of information for each web page.
So i have a list of around 7000 barcodes that i want to pass to this site 'https://www.barcodelookup.com/' (you just add the barcode after the backslash), then pull back the manufacturer of that product which is in the span "product-text".I'm currently trying to get it to run with the below;
from bs4 import BeautifulSoup
import requests
source = requests.get('https://www.barcodelookup.com/194398882321')
soup = BeautifulSoup(source, 'lxml')
#print(soup.prettify())
price = soup.find('span', {'class' : 'product-text'})
print(price.text)
This gives an error as below;
TypeError: object of type 'Response' has no len()
Any help would be greatly appreciated, thanks
CodePudding user response:
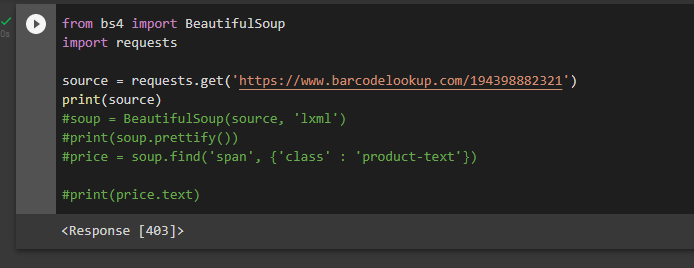 the website has been blocking the web scrapping and returning an 403 error. This results in getting nothing for you request and raises an error
the website has been blocking the web scrapping and returning an 403 error. This results in getting nothing for you request and raises an error
CodePudding user response:
If you inspect the source, you will see that the response status is 403 and the overall source.text reveals that the website is protected by Cloudflare. This means that using requests is not really helpful for you. You need the means to overcome the 'antibot' protection from Cloudflare. Here are two options:
1. Use a third party service
I am an engineer at WebScrapingAPI and I can recommend you our web scraping API. We're preventing detection by using various proxies, IP rotations, captcha solvers and other advanced features. A basic example of using our API for your scenarios is:
import requests
API_KEY = '<YOUR_API_KEY>'
SCRAPER_URL = 'https://api.webscrapingapi.com/v1'
TARGET_URL = 'https://www.barcodelookup.com/194398882321'
PARAMS = {
"api_key":API_KEY,
"url": TARGET_URL,
"render_js":1,
"timeout":"20000",
"proxy_type": "residential",
"extract_rules":'{"elements":{"selector":"span.product-text","output":"text"}}',
}
response = requests.get(SCRAPER_URL, params=PARAMS )
print(response.text)
Response:
{"elements":["\nUPC-A 194398882321, EAN-13 0194398882321\n","Media ","Sony Uk ","\n1-2-3: The 80s CD.\n"]}
2. Build an undetectable web scraper
You can also try building a more 'undetectable' web scraper on your end. For example, try using a real browser for your scraper, instead of requests. Selenium would be a good place to start. Here is an implementation example:
from bs4 import BeautifulSoup
from selenium import webdriver
from selenium.webdriver.support.ui import WebDriverWait
BASE_URL = 'https://www.barcodelookup.com/194398882321'
driver = webdriver.Chrome()
wait = WebDriverWait(driver, 5000)
driver.get(BASE_URL)
html = driver.page_source
soup = BeautifulSoup(html, 'html.parser')
price = soup.find('span', {'class' : 'product-text'})
print(price)
driver.quit()
In time though, Cloudflare might flag your 'fingerprint' and block your requests. Some more things you could add to your project are: