I have a trivial question regarding the aggregate statistic on spark\pyspark
I was not able to find an answer here on stack overflow, neither on the doc
Assuming a column like this one:
|COL |
|null |
|null |
|null |
|14.150919 |
|1.278803 |
|null |
|null |
|null |
|60.593151 |
|null |
|2.393357 |
|null |
|null |
|null |
|null |
when I extract a statistic like the mean\average, which is calculated as:
df.agg(F.avg('COL').alias('average'))
I'am assuming that the average is calculated as:
sum_of_values_not_null / number_of_values_not_null
where:
sum_of_values_not_null = 14.150919 1.278803 60.593151 2.393357
number_of_values_not_null = 4
my question is: does the average\standard deviation or any statistic count in the denominator also the null values? changing
number_of_values_not_null = 4
to
number_of_values_not_null = 16
I suppose no, because it should be conceptually uncorrect, because the statistic should count only the values if they are not null (doing so would assume that the null values are 0's).
CodePudding user response:
This is my take. I would answer using the query plan. Use explain(True) to get the logical optimization plan
df.agg(F.avg('COL').alias('average')).explain(True)
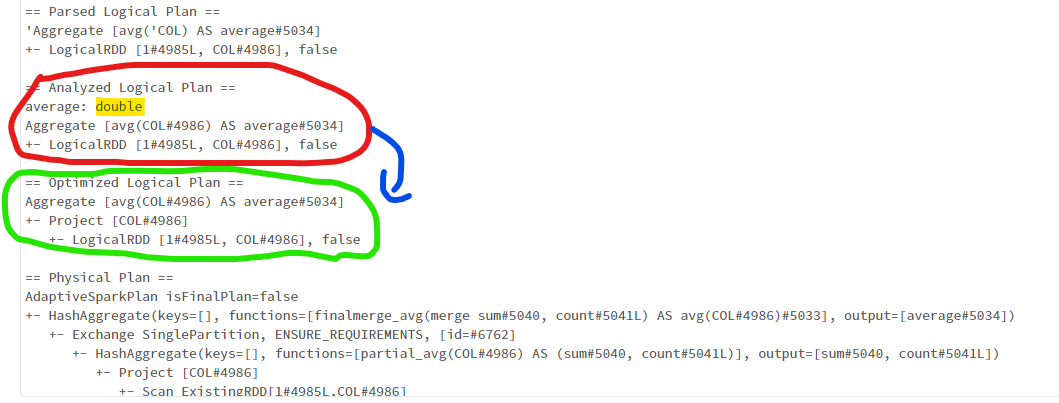
The analyzed logical plan (circled red) seems to indicate only dtypes doubles will be averaged
It's not the analyzed plan that gets implemented. The optimizer reads the analysed plans and optimizes it if needed.
In this case, the optimized plan (circled green) is a replica of the analyzed plan. It's reasonable to conclude the nulls were excluded from the summation and average computation.
This is not unusual behavior for spark. The query Optimizer always begins by eliminating nulls. If you were to do any kind of filter, you will observe the physical plan always begins by excluding nulls, whether nulls were part of the filter condition or not.