In this sample data:
data = [{'source': ' Off-grid energy'},
{'source': 'off-grid generation'},
{'source': 'Off grid energy '},
{'source': 'OFFGRID energy'},
{'source': 'apple sauce'},
{'source': 'green energy'},
{'source': 'Green electricity '},
{'source': 'tomato sauce'},
{'source': 'BIOMASS as an energy source'},
{'source': 'produced heat (biogas).'}]
I want to create a new column based on conditions:
my_conditions = {
"green": df["source"].str.contains("green"),
"bio-gen": df["source"].str.contains("bio"),
"off-grid": df["source"].str.contains("off-grid")
}
I preprocess by lowercasing df["source"]:
df['source'] = df["source"].str.lower()
Then using Numpy's select:
df['category-lower'] = np.select(my_conditions.values(),\
my_conditions.keys(),\
default="other")
I can't figure out why the lowercasing is not recognized (see row 0, 6, 8)
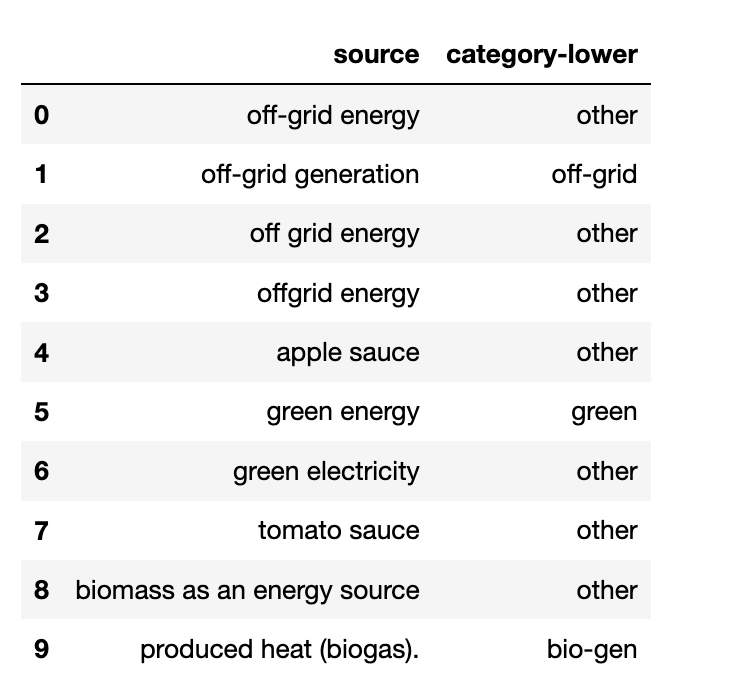
CodePudding user response:
You've probably applied .str.lower() after the my_condition was constructed. Try instead:
import re
# apply .str.lower() here, or use flags=re.I (ignorecase in .str.contains)
# df['source'] = df["source"].str.lower()
my_conditions = {
"green": df["source"].str.contains("green", flags=re.I),
"bio-gen": df["source"].str.contains("bio", flags=re.I),
"off-grid": df["source"].str.contains("off-grid", flags=re.I),
}
df["category-lower"] = np.select(
my_conditions.values(), my_conditions.keys(), default="other"
)
print(df)
Prints:
source category-lower
0 Off-grid energy off-grid
1 off-grid generation off-grid
2 Off grid energy other
3 OFFGRID energy other
4 apple sauce other
5 green energy green
6 Green electricity green
7 tomato sauce other
8 BIOMASS as an energy source bio-gen
9 produced heat (biogas). bio-gen