what's up?
I am having a little problem, where I need to use the pandas dropna function to remove rows from my dataframe. However, I need it to not delete the unique values from my dataframe.
Let me explain better. I have the following dataframe:
| id | birthday |
|---|---|
| 0102-2 | 09/03/2020 |
| 0103-2 | 14/03/2020 |
| 0104-2 | NaN |
| 0105-2 | NaN |
| 0105-2 | 25/03/2020 |
| 0108-2 | 07/04/2020 |
In the case above, I need to delete the row from my dataframe based on the NaN values in the birthday column. However, as you can see the id "0104-2" is unique unlike the id "0105-2" where it has a NaN value and another with a date. So I would like to keep track of all the lines that have NaN that are unique.
Is it feasible to do this with dropna, or would I have to pre-process the information beforehand?
CodePudding user response:
You could sort by the birthday column and then drop duplicates keeping the first out of the two, by doing the following:
The complete code would look like this:
import pandas as pd
import numpy as np
data = {
"id": ['102-2','103-2','104-2', '105-2', '105-2', '108-2'],
"birthday":['09/03/2020', '14/03/2020', np.nan, np.nan, '25/03/2020', '07/04/2020']
}
df = pd.DataFrame(data)
df.sort_values(['birthday'], inplace=True)
df.drop_duplicates(subset="id", keep='first', inplace=True)
df.sort_values(['id'], inplace=True)
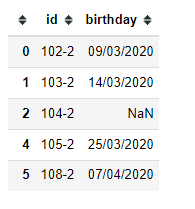
CODE EXPLANATION: Here is the original dataframe:
import pandas as pd
import numpy as np
data = {
"id": ['102-2','103-2','104-2', '105-2', '105-2', '108-2'],
"birthday":['09/03/2020', '14/03/2020', np.nan, np.nan, '25/03/2020', '07/04/2020']
}
df = pd.DataFrame(data)
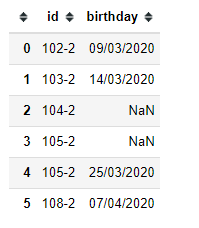
Now sort the dataframe:
df.sort_values(['birthday'], inplace=True)
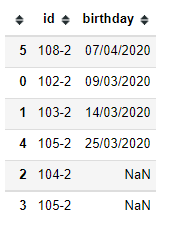
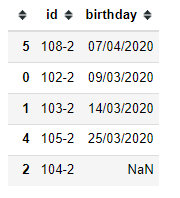
Then drop the duplicates based on the id column. Keeping only the first value.
df.drop_duplicates(subset="id", keep='first', inplace=True)
CodePudding user response:
Sorry I read your requirement wrongly.. Should sort first then using shift()
df.sort_values(by='id', na_position='first', inplace=True)
df.loc[(df['birthday'].notna()) | (df['id'].shift(-1) != df['id'])]
Original Answer:
You can filter using notna() or duplicated()
df.loc[(df['birthday'].notna()) | (df.duplicated(subset='id', keep=False))]
CodePudding user response:
I could do this by grouping by id and aggregating with .agg('first'):
# added a couple more rows to show the behaviour
df = pd.DataFrame({'id': ['0102-2', '0102-2', '0103-2', '0103-2', '0104-2', '0105-2', '0105-2', '0108-2'],
'birthday': ['09/03/2020', np.nan, '14/03/2020', '12/03/2020', np.nan, np.nan, '25/03/2020', '07/04/2020']})
df
# Output:
id birthday
0 0102-2 09/03/2020
1 0102-2 NaN # duplicate id with NaN goes second
2 0103-2 14/03/2020
3 0103-2 12/03/2020 # duplicate id with an earlier date
4 0104-2 NaN # unique with NaN
5 0105-2 NaN # duplicate with NaN goes first
6 0105-2 25/03/2020
7 0108-2 07/04/2020
df.groupby('id').agg('first').reset_index()
# Output:
id birthday
0 0102-2 09/03/2020
1 0103-2 14/03/2020
2 0104-2 None
3 0105-2 25/03/2020
4 0108-2 07/04/2020
CodePudding user response:
I hope this is what you wanted:
import numpy as np
import pandas as pd
df = pd.DataFrame({'id': [1, 2, 3, 3, 4], 'birthday': [1994, np.nan, np.nan, 2019, 2020]})
df["id_count"] = df.groupby('id')['id'].transform('count') # helper column to identify unique ids
df_filtered = df[(df["id_count"] > 1) & df["birthday"].isna() == False] # filter out nans within non-unique ids
df_filtered.drop(["id_count"], axis=1) # drop helper column
output
id birthday
0 1 1994.0
1 2 NaN
3 3 2019.0
4 4 2020.0