my dataset look similiar to this (but with a couple of more rows):
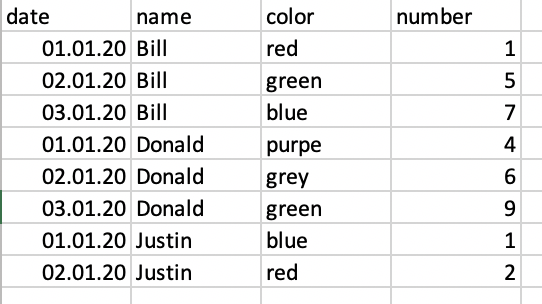
The aim is to get this:

What I tried to do is:
# Identify names that are in the dataset
names = df['name'].unique().tolist()
# Define dataframe with first name
df1 = pd.DataFrame()
df1 = df[(df == names[0]).any(axis=1)]
df1 = df1.drop(['name'], axis=1)
df1 = df1.rename({'color':'color_' str(names[0]), 'number':'number_' str(names[0])}, axis=1)
# Make dataframes with other names and their corresponding color and number, add them to df1
df_merged = pd.DataFrame()
for i in range(1, len(names)):
df2 = pd.DataFrame()
df2 = df[(df == names[i]).any(axis=1)]
df2 = df2.drop(['name'], axis=1)
df2 = df2.rename({'color':'color_' str(names[i]), 'number':'number_' str(names[i])}, axis=1)
df_merged = df1.join(df2, lsuffix="_left", rsuffix="_right", how='left')
In the end I get this result for df_merged:
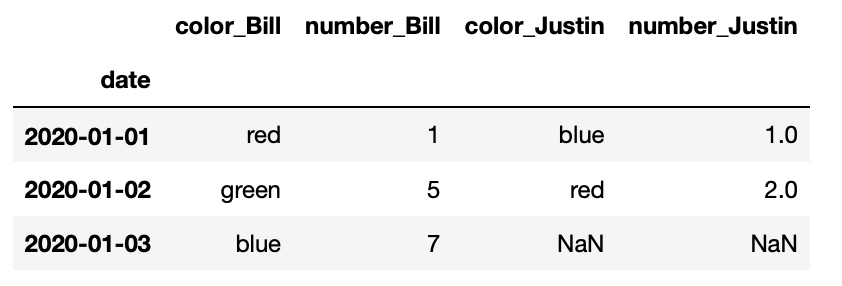
As you can see the columns color_Donald and number_Donald are missing. Does anyone know why and how to improve the code? It seems as if the loop somehow skips or overwrites Donald.
Thanks in advance!
CodePudding user response:
sample df
import pandas as pd
data = {'name': {'2020-01-01 00:00:00': 'Justin', '2020-01-02 00:00:00': 'Justin', '2020-01-03 00:00:00': 'Donald'}, 'color': {'2020-01-01 00:00:00': 'blue', '2020-01-02 00:00:00': 'red', '2020-01-03 00:00:00': 'green'}, 'number': {'2020-01-01 00:00:00': 1, '2020-01-02 00:00:00': 2, '2020-01-03 00:00:00': 9}}
df = pd.DataFrame(data)
print(f"{df}\n")
name color number
2020-01-01 00:00:00 Justin blue 1
2020-01-02 00:00:00 Justin red 2
2020-01-03 00:00:00 Donald green 9
final df
df = (
df
.reset_index(names="date")
.pivot(index="date", columns="name", values=["color", "number"])
.fillna("")
)
df.columns = ["_".join(x) for x in df.columns.values]
print(df)
color_Donald color_Justin number_Donald number_Justin
date
2020-01-01 00:00:00 blue 1
2020-01-02 00:00:00 red 2
2020-01-03 00:00:00 green 9
CodePudding user response:
The problem is the line:
df_merged = df1.join(df2, lsuffix="_left", rsuffix="_right", how='left')
where df_merged will be set in the loop always to the join of df1 with current df2.
The result after the loop is therefore a join of df1 with the last df2 and the Donald gets lost in this process.
To fix this problem first join empty df_merged with df1 and then in the loop join df_merged with df2.
Here the full code with the changes (not tested):
# Identify names that are in the dataset
names = df['name'].unique().tolist()
# Define dataframe with first name
df1 = pd.DataFrame()
df1 = df[(df == names[0]).any(axis=1)]
df1 = df1.drop(['name'], axis=1)
df1 = df1.rename({'color':'color_' str(names[0]), 'number':'number_' str(names[0])}, axis=1)
# Make dataframes with other names and their corresponding color and number, add them to df1
df_merged = pd.DataFrame()
df_merged = df_merged.join(df1) # <- add options if necessary
for i in range(1, len(names)):
df2 = pd.DataFrame()
df2 = df[(df == names[i]).any(axis=1)]
df2 = df2.drop(['name'], axis=1)
df2 = df2.rename({'color':'color_' str(names[i]), 'number':'number_' str(names[i])}, axis=1)
# join the current df2 to df_merged:
df_merged = df_merged.join(df2, lsuffix="_left", rsuffix="_right", how='left')