I'm trying to pull some data from yfinance in Python for different funds from different exchanges. In pulling my data I just set-up the start and end dates through:
start = '2002-01-01'
end = '2022-06-30'
and pulling it through:
assets = ['GOVT', 'IDNA.L', 'IMEU.L', 'EMMUSA.SW', 'EEM', 'IJPD.L', 'VCIT',
'LQD', 'JNK', 'JNKE.L', 'IEF', 'IEI', 'SHY', 'TLH', 'IGIB',
'IHYG.L', 'TIP', 'TLT']
assets.sort()
data = yf.download(assets, start = start, end = end)
I guess you've noticed that the "assets" or the ETFs come from different exchanges such as ".L" or ".SW".
Now the result this:
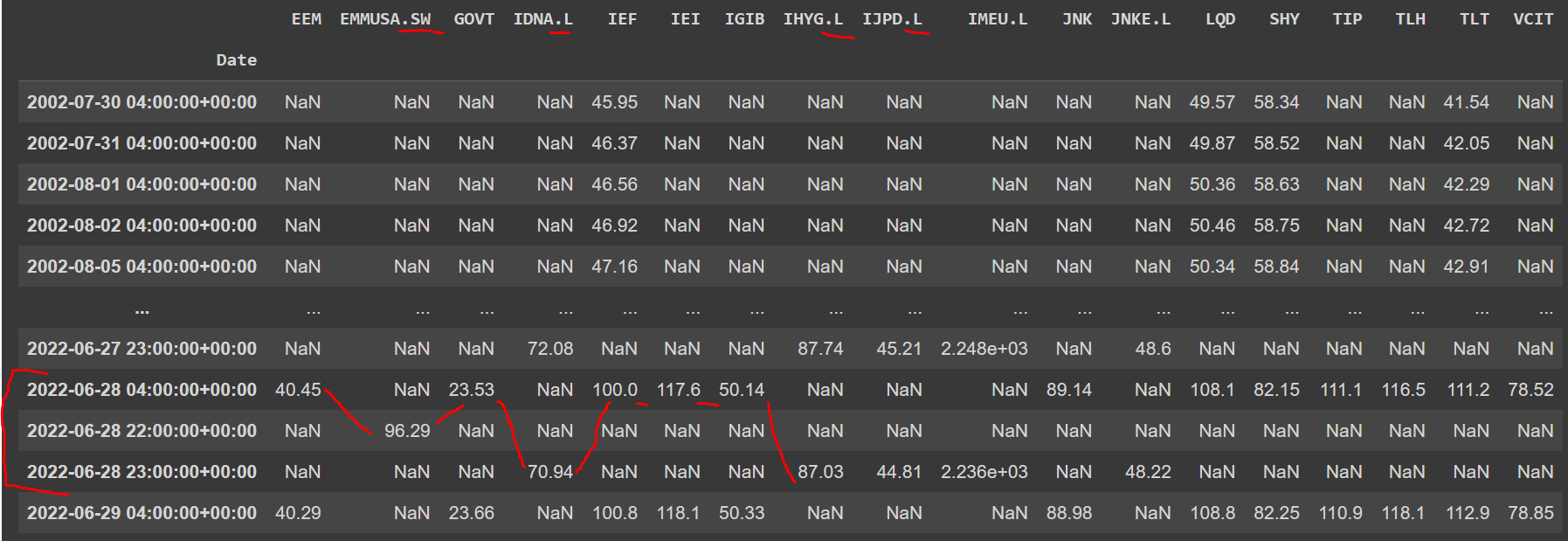
It seems to me that there is no overlap for a single instrument (i.e. two prices for the same day). So I don't think the data will be disturbed if any scrubbing or clean-up is done.
So my goal is to harmonize or consolidate the prices to its date index rather than date-and-time index so that each price for each instrument is firmly side-by-side each other for a particular date.
Thanks!
CodePudding user response:
If you want the daily last closing price from the yahoo-finance api you could use the interval argument,
yf.download(assets, start=start, end=end, interval="1d")
Solution with Pandas:
Transforming the Index
You have an index where each row is a string representing the datetime. You firstly want to transform those strings to an actual DatetimeIndex where each row will be of type datetime64. This is done in order to easily work with dates in you dataset applying functions from the datetime library. Finally, you pick the date from each datetime64;
data.index = pd.to_datetime(data.index).date
Groupby
Now that you have an index of dates you can groupby on index. Firstly, you want to deal with NaN values. If you want that the closing price is only considered to fill the values within the date itself only you want to apply:
data= data.groupby(data.index).ffill()
Otherwise, if you think that the closing price of (e.g.) the 1st October can be used not only to filter values in the 1st October but also 2nd and 3rd of October which have NaN values, simply apply the ffill() without the groupby;
data= data.ffill()
Lastly, taking last observed record grouping for date (Index); Note that you can apply all the functions you want here, even a custom lambda;
data = data.groupby(data.index).last()