The applyInPandas method can be used to apply a function in parallel to a GroupedData pyspark object as in the minimal example below.
import pandas as pd
from time import sleep
from pyspark.sql import SparkSession
# spark session object
spark = SparkSession.builder.getOrCreate()
# test function
def func(x):
sleep(1)
return x
# run test function in parallel
pdf = pd.DataFrame({'x': range(8)})
sdf = spark.createDataFrame(pdf)
sdf = sdf.groupby('x').applyInPandas(func, schema=sdf.schema)
dx = sdf.toPandas()
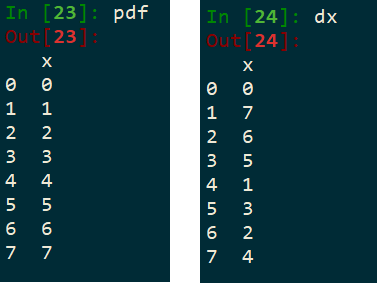
The minimal example has been tested on an 8 CPU single node system (eg a m5.4xlarge Amazon EC2 instance) and takes approximately 1 second to run, as the one-second sleep function is applied to each of 8 CPUs in parallel. pdf and dx objects are in the screenshot below.
My issue is how to run the same minimal example on a cluster, eg an Amazon EMR cluster. So far, after setting up a cluster the code is being executed with a single core, so the code will require appx 8 sec to run (each function executed in series).
UPDATE
Following @Douglas M's answer, the following code parallelizes on an EMR cluster
import pandas as pd
from datetime import datetime
from time import sleep
# test function
def func(x):
sleep(1)
return x
# run and time test function
sdf = spark.range(start=0, end=8, step=1, numPartitions=8)
sdf = sdf.groupby('id').applyInPandas(func, schema=sdf.schema)
now = datetime.now()
dx = sdf.toPandas()
print((datetime.now() - now).total_seconds()) # 1.09 sec
However using repartition does not parallelize. Note that this works on a single node EC2 instance, just not on the EMR cluster.
import pandas as pd
from datetime import datetime
from time import sleep
# test function
def func(x):
sleep(1)
return x
# run and time test function
pdf = pd.DataFrame({'x': range(8)})
sdf = spark.createDataFrame(pdf)
sdf = sdf.groupby('x').applyInPandas(func, schema=sdf.schema)
sdf = sdf.repartition(8)
now = datetime.now()
dx = sdf.toPandas()
print((datetime.now() - now).total_seconds()) # 8.33 sec
Running the above code, the spark progressbar first indicates 8 tasks then switches to 1 task.

CodePudding user response:
Spark's parallelism is based on the number of partitions in the dataframe it is processing. Your sdf dataframe has only one partition because it is very small.
It would be better to first create your range with the SparkSession.range(start: int, end: Optional[int] = None, step: int = 1, numPartitions: Optional[int] = None) → pyspark.sql.dataframe.DataFrame api (docs).
For a quick fix, add repartition:
sdf = spark.createDataFrame(pdf).repartition(8)
Which will put each of the 8 elements into their own partition. The partitions can then be processed by separate worker cores.