I have data that is structure like such:
actor_data <- structure(list(id = c(123L, 456L, 789L, 912L, 235L), name = c("Tom Cruise",
"Will Smith", "Ryan Reynolds", "Chris Rock", "Emma Stone"), locationid1 = c(5459L,
NA, 6114L, NA, NA), location1 = c("Paris, France", "", "Brooklyn, NY",
"", ""), locationid2 = c(NA, 5778L, NA, NA, 4432L), location3 = c("",
"Dolby Theater", "", "", "Hollywood"), locationid3 = c(NA, 2526L,
3101L, NA, NA), location3.1 = c("", "London", "Boston", "", ""
), locationid4 = c(6667L, 2333L, 1118L, NA, NA), location4 = c("Virginia",
"Maryland", "Washington", "", "")), class = "data.frame", row.names = c(NA,
-5L))
I am trying to make the location data run vertically instead of horizontally while also making sure its not accounting for blank fields.
So the final result will look like this:
actor_data_exp <- structure(list(id = c(123L, 123L, 456L, 456L, 456L, 789L, 789L,
789L, 235L), name = c("Tom Cruise", "Tom Cruise", "Will Smith",
"Will Smith", "Will Smith", "Ryan Reynolds", "Ryan Reynolds",
"Ryan Reynolds", "Emma Stone"), locationid = c(5459L, 6667L,
5778L, 2526L, 2333L, 6114L, 3101L, 1118L, 4432L), location = c("Paris, France",
"Virginia", "Dolby Theater", "London", "Maryland", "Brooklyn, NY",
"Boston", "Washington", "Hollywood")), class = "data.frame", row.names = c(NA,
-9L))
Or to give you a visual, will end up looking like this:
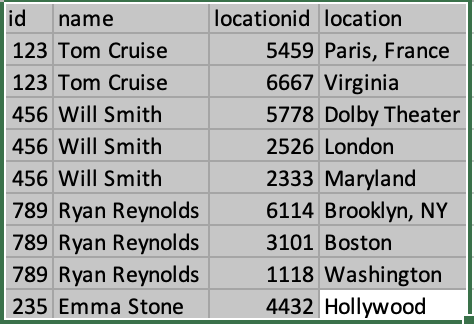
CodePudding user response:
I would rename the columns that start with "location", so that there is an underscore before the number in each column name. Then use pivot_longer with the underscore as name_sep, and using c(".value", "var") in the names_to argument that to ensure both location and locationid have their own columns. This will also create the redundant column var which will contain the numbers 1-4 that were appended to the original column names.
Finally, filter out missing values and remove the redundant var column.
library(tidyverse)
actor_data %>%
rename_with(~ ifelse(grepl("location", .x),
sub("^(.*?)([0-9]\\.?\\d?)$", "\\1_\\2", .x), .x)) %>%
pivot_longer(starts_with("location"),
names_sep = "_", names_to = c(".value", "var")) %>%
filter(!is.na(locationid) & !is.na(location) & nzchar(location)) %>%
select(-var)
#> # A tibble: 6 x 4
#> id name locationid location
#> <int> <chr> <int> <chr>
#> 1 123 Tom Cruise 5459 Paris, France
#> 2 123 Tom Cruise 6667 Virginia
#> 3 456 Will Smith 2526 Dolby Theater
#> 4 456 Will Smith 2333 Maryland
#> 5 789 Ryan Reynolds 6114 Brooklyn, NY
#> 6 789 Ryan Reynolds 1118 Washington