I have a text file that I want to parse into a dataframe in R.
The text is a collection of poems from the Gutenberg Project (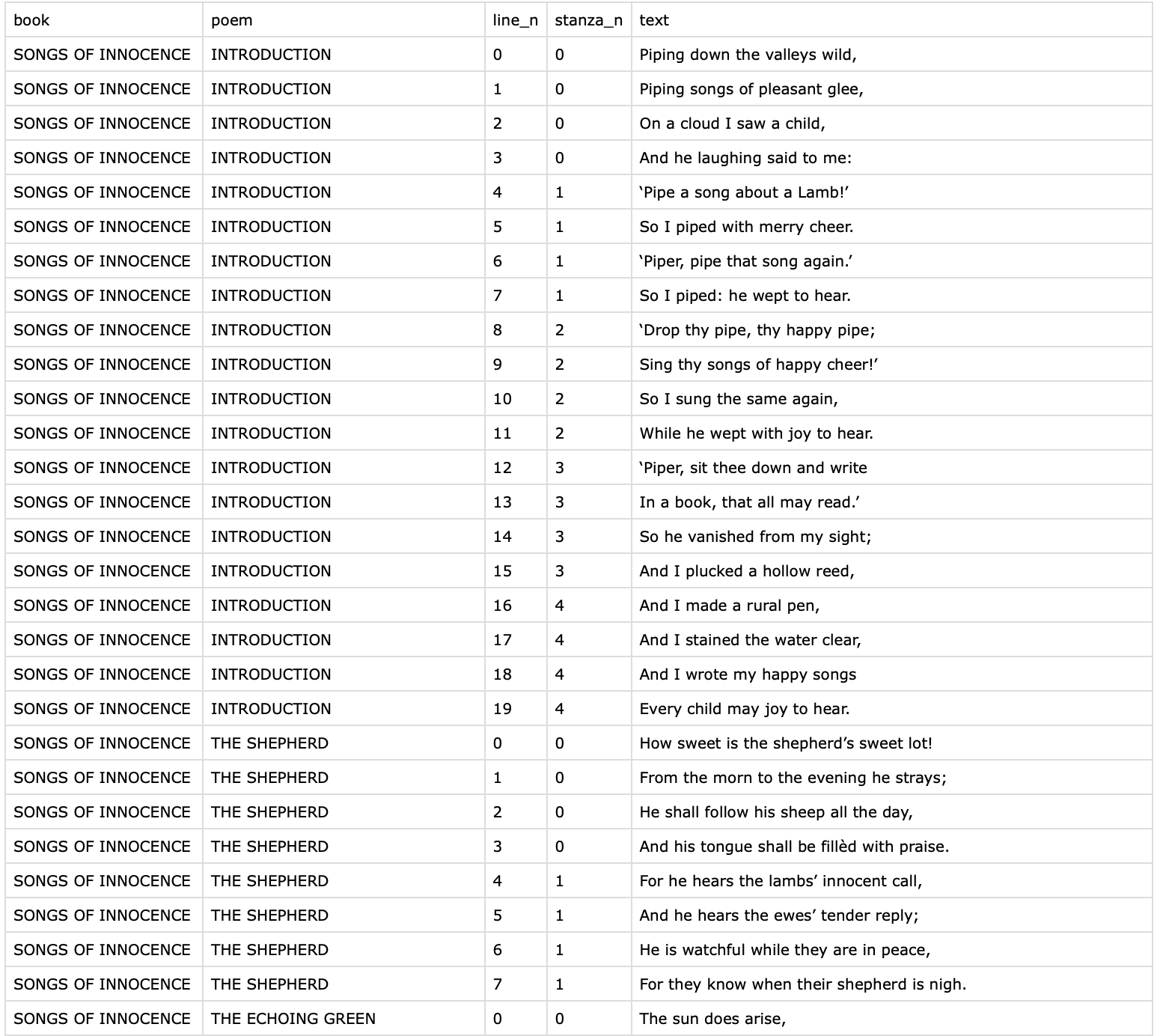
I have managed to split the text, so I now have several nested lists with information on the stanzas and lines and a few character strings with the poem titles.
Here is the code I have so far:
# [1] load the data into the environment
## WITH GUTENBERGR PACKAGE
blake <- gutenberg_download(1934, mirror = "http://mirrors.xmission.com/gutenberg/") %>%
select("text")
# [2] turn data into vector ??
blake_v <- as.vector(unlist(blake['text'])) # This gives each line as a string
blake_parse <- parse(text = blake)
# [3] splitting the text
books <- str_split(blake_parse,"SONGS OF EXPERIENCE")[[1]] # splitting the text into the two books - 3 chunks: with content, songs of innocence and songs of experience
i <- books[[2]] # Songs of innocence including table of content at the beginning
i <- str_split(i,"SONGS OF INNOCENCE")[[1]] # spliting the table of content from the poems
i <- i[[2]] # Songs of Innocence Poems - just the poems in one string
i <- str_split(i,'\"\", \"\", \"\", \"\",')[[1]] # splitting into the separate poems
e <- books[[3]] # Songs of Experience - just the poems
e <- str_split(e,'\"\", \"\", \"\", \"\",')[[1]] # splitting into the separate poems
i_titles <- str_extract_all(i, "[A-Z]{2,}") # extracting the titles
i_titles <- str_c(i_titles) # combine string elements into one string element
e_titles <- str_extract_all(e, "[A-Z]{2,}") # extracting the titles
e_titles <- str_c(e_titles)
i_poems <- str_remove_all(i, "[A-Z]{2,}") # poem texts without the titles
e_poems <- str_remove_all(e, "[A-Z]{2,}") # poem texts without the titles
i_stanza <- str_split(i_poems, '\", \"\", \"') # spliting the text further into stanzas
e_stanza <- str_split(e_poems, '\", \"\", \"') # splitting the text furhter into stanzas
i_lines <- str_split(i_stanza, '\", ')
e_lines <- str_split(e_stanza, '\", ')
I think I have all the relevant information, but I don't know how to convert all the information into a dataframe including the numbers of the lines and stanzas.
This is what I did to create a dataframe which includes each line of poem in a row but I don't know how to integrate the other information.
df <- data.frame(matrix(unlist(i_lines), nrow=TRUE, byrow=TRUE),stringsAsFactors=FALSE)
df <- pivot_longer(df,
cols = starts_with("x"),
names_to = "text",
values_to = "value")
I'm grateful for any tips and recommendations.
CodePudding user response:
I think that you might be able to simplify this quite a bit given that the text is so structured. What I have done below is take the original tibble created from the gutenburg_download() command and then group by book title (the only time that SONG starts a line with no white space), then by poem (only lines that start with all-caps), then by stanza (separated by one line of white space).
The book_titles and poem_titles are vectors containing the values of the book titles and poem titles, respectively, that we use to label factor variables created based on the book and poem numbers.
library(gutenbergr)
library(dplyr)
blake <- gutenberg_download(1934, mirror = "http://mirrors.xmission.com/gutenberg/") %>%
select("text")
blake_new <- blake |>
mutate(
# Find where each book starts and then create book number based
# on cumulative sum of how many books have been present
bookstarts = as.numeric(grepl("^SONGS", text)),
booknum = cumsum(bookstarts)
) %>%
# Remove front matter & table of contents
filter(booknum > 0)
# Gather book titles
book_titles <- blake_new %>%
filter(bookstarts != 0) %>%
pull(text)
blake_new <- blake_new %>%
mutate(
# Label factor values then turn into character string based on labels
book = factor(booknum, labels = book_titles) %>% as.character()
) %>%
# Remove lines containing book titles
filter(!grepl("(SONGS OF INNOCENCE|SONGS OF EXPERIENCE)", text)) %>%
mutate(
# Lagged variable copies data moved down by one row (will be used below
# to remove repeated blank lines)
lagged = lag(text),
# Find where each poem starts based on having two or more capital letters
poemstarts = as.numeric(grepl("^[A-Z]{2,}", text, perl = TRUE))
) %>%
# Remove rows were both the text and the lagged variables are empty strings
# (removes repeated blank lines in `text` variable)
filter(!(text == "" & lagged == "")) %>%
select(-lagged) %>%
mutate(
# Creat poem number based on how many poems have come before
poemnum = cumsum(poemstarts)
)
# Gather poem titles
poem_titles <- blake_new %>%
filter(poemstarts > 0) %>%
pull(text)
blake_new <- blake_new %>%
mutate(
# Label poem factor variables and turn into a string variable
poem = factor(poemnum, labels = poem_titles) %>% as.character()
) %>%
group_by(poem) %>%
mutate(
# Find where stanzas start by finding blank lines of text and then
# create stanza number within each poem based on number of stanzas that
# came before
stanzastarts = as.numeric(grepl("^$", text)),
stanza_n = cumsum(stanzastarts),
) %>%
# Remove blank lines separating stanzas and poem titles
filter(!grepl("^$", text) & !(stanza_n == 0)) %>%
# Create line numbers and zero-index stanza numbers
mutate(
line_n = 1:n() - 1,
stanza_n = stanza_n - 1
) %>%
select(book, poem, line_n, stanza_n, text)