I have a huge csv file with approximately 992 rows * 992columns.
The file for example looks like this:
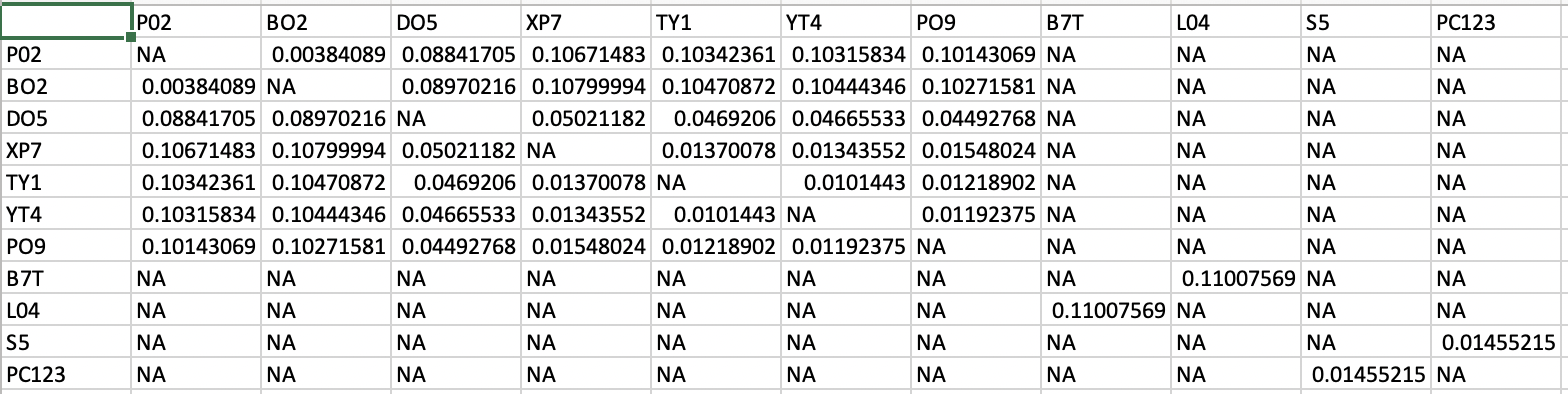
I need to create an output file that essentially contains a header and looks like below:

I tried to use csv reader and dict reader too but i am getting stuck on removing NA columns and also getting the name of the column into one list (or column) and the corresponding value into another. I am not at all good at pandas and clueless in that aspect.
I tried:
def csv_reader():
with open("/Users/svadali/Downloads/test_1.csv") as csv_infile, open("/Users/svadali/Downloads/result_file.txt", "w ") as outfile:
reader = csv.reader(csv_infile, delimiter=',')
file_writer = csv.writer(outfile, delimiter="\t")
file_writer.writerow(["SPC", "SPCs_within_0.2_phylo_distance", "Phylo_Distances"])
for row in reader:
for column in reader:
print("this is row", row)
print("this is column", column)
if column == 'NA':
print("this non NA", column)
print("this is supposed to be non NA row", row)
break
I also trie transpose but they are not yielding the results I need.
CodePudding user response:
You can extract the names from the header, zip them with the distances in each row, filter those with invalid distances, and then zip them again to produce names and distances in separate columns:
with open("test_1.csv") as infile, open("result_file.txt", "w ") as outfile:
reader = csv.reader(infile, delimiter=',')
writer = csv.writer(outfile, delimiter="\t")
writer.writerow(["SPC", "SPCs_within_0.2_phylo_distance", "Phylo_Distances"])
_, *names = next(reader)
for name, *distances in reader:
writer.writerow((
name,
*map(
','.join,
zip(*((n, d) for n, d in zip(names, distances) if d != 'NA'))
)
))
Demo: https://replit.com/@blhsing/OutrageousInvolvedProtools