I have a string as below
33f04e43cc6","from":"/ABC001/data/ZZZ000_logger_v1_20221010053935242_1.zip","to":"/ABC001/data/ZZZ000_logger_v1_20221010053935242_1.zip","remove":true,"objectId":"229bea5a-c9b0-4ad0-aecc-84a63bc7dc6f"}2022-10-10 05:39:35,247 Platform.Interface: Published message to topic: {"id":"a32e6cbe-94d4-493f-ae56-933f04e43cc6"}, "from":"/ABC001/data/ZZZ000_single_3445442_1.zip"
I need to extract file names ZZZ000_logger_v1_20221010053935242_1.zip, ZZZ000_single_3445442_1.zip from this.
I have just shared a snapshot of the string. I used to get more file names in that pattern. In the above example, 'logger_v1' and 'single' strings will always be present in the mentioned format in the string
So the format of the filenames will be like that only as mentioned
AnyAlphanumericCharacter_logger_v1_AnyNumeric_1.zip
AnyAlphanumericCharacter_single_AnyNumeric_1.zip
I tried using regex as below
match = re.findall("^\W.*zip$", str)
It will output /ABC001/data/ZZZ000_logger_v1_20221010053935242_1.zip
I am not sure how to provide dynamic and static characters search patterns in regex.
I will have list of file names like that and need to remove duplicates at the end.
CodePudding user response:
Try this,
In [1]: re.match(r'.*data/([^"] ).*', s).group(1)
Out[1]: 'ZZZ000_logger_v1_20221010053935242_1.zip'
Regex diagram. 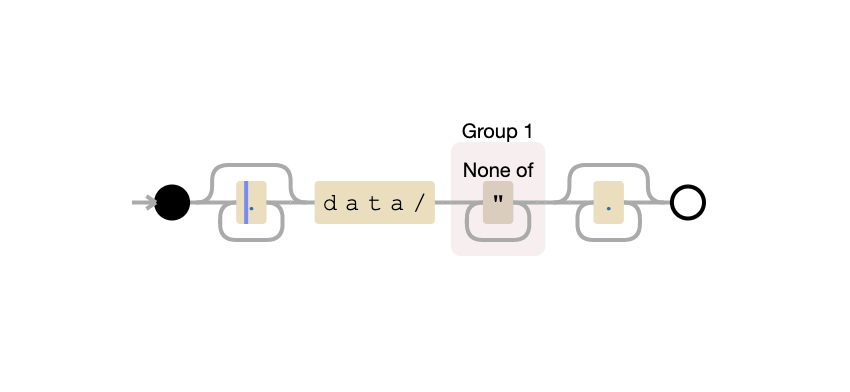
CodePudding user response:
As suggested by Rahul I used it in a similar pattern with slight changes.
regex = re.compile(".{0,}data/([^\"]{1,}).{0,}")
testString = '*****'
matchArray = regex.findall(testString)
Then I got all the matching file names with *.zip as an iterable array.
Thanks!