Suppose you have a basic toy system that finds and processes all files in a directory (for some definition of "processes"). A basic diagram of how it operates could look like:
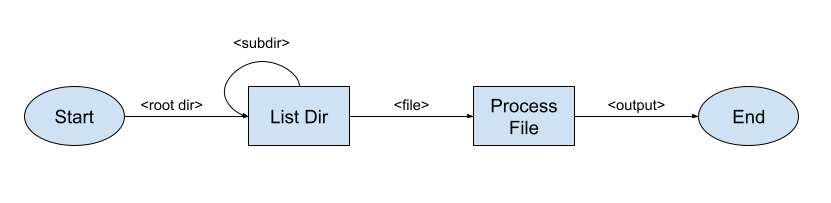
If this were a real-world distributed system, the "arrows" could actually be unbounded queues, and then it just works.
In a self-contained go application, it's tempting to model the "arrows" as channels. However, due to the self-referential nature of "generating more work by needing to list subdirectories", it's easy to see that a naive implementation would deadlock. For example (untested, forgive compile errors):
func ListDirWorker(dirs, files chan string) {
for dir := range dirs {
for _, path := range ListDir(dir) {
if isDir(path) {
dirs <- path
} else {
files <- path
}
}
}
}
}
If we imagine we've configured just a single List worker, all it takes is for a directory to have two subdirectories to basically deadlock this thing.
My brain wants there to be "unbounded channels" in golang, but the creators don't want that. What's the correct idiomatic way to model this stuff? I imagine there's something simpler than implementing a thread-safe queue and using that instead of channels. :)
CodePudding user response:
Had a very similar problem to solve. Needed:
- finite number of recursive workers (bounded parallelism)
- content.Context for early cancelations (enforce timeout limits etc.)
- partial results (some goroutines hit errors while others did not)
- crawl completion (worker clean-up etc.) via recursive depth tracking
Below I describe the problem and the gist of the solution I arrived at
Problem: scrape a HR LDAP directory with no pagination support. Server-side limits also precluded bulk queries greater than 100K records. Needed small queries to work around these limitations. So recursively navigated the tree from the top (CEO) - listing employees (nodes) and recursing on managers (branches).
To avoid deadlocks - a single workItem channel was used not only by workers to read (get) work, but also to write (delegate) to other idle workers. This approach allowed for fast worker saturation.
Note: not included here, but worth adding, is to use a common API rate-limiter to avoid multiple workers collectively abusing/exceeding any server-side API rate limits.
To start the crawl, create the workers and return a results channel and an error channel. Some notes:
c.intheworkItemchannel must be unbuffered for delegation to work (more on this later)c.rwgtracks collective recursion depth for all worker. When it reaches zero, all recursion is done and the crawl is complete
func (c *Crawler) Crawl(ctx context.Context, root Branch, workers int) (<-chan Result, <-chan error) {
errC := make(chan error, 1)
c.rwg = sync.WaitGroup{} // recursion depth waitgroup (to determine when all workers are done)
c.rwg.Add(1) // add to waitgroups *BEFORE* starting workers
c.in = make(chan workItem) // input channel: shared by all workers (to read from and also to write to when they need to delegate)
c.out = make(chan Result) // output channel: where all workers write their results
go func() {
workerErrC := c.createWorkers(ctx, workers)
c.in <- workItem{
branch: root, // initial place to start crawl
}
for err := range workerErrC {
if err != nil {
// tally for partial results - or abort on first error (see werr)
}
}
// summarize crawl success/failure via a single write to errC
errC <- werr // nil, partial results, aborted early etc.
close(errC)
}
return c.out, errC
}
Create a finite number of individual workers. The returned error channel receives an error for each individual worker:
func (c *Crawler) createWorkers(ctx context.Context, workers int) (<-chan error) {
errC := make(chan error)
var wg sync.WaitGroup
wg.Add(workers)
for i := 0; i < workers; i {
i := i
go func() {
defer wg.Done()
var err error
defer func() {
errC <- err
}()
conn := Dial("somewhere:8080") // worker prep goes here (open network connect etc.)
for workItem := range c.in {
err = c.recurse(ctx, i 1, conn, workItem)
if err != nil {
return
}
}
}()
}
go func() {
c.rwg.Wait() // wait for all recursion to finish ...
close(c.in) // ... so safe to close input channel ...
wg.Wait() // ... wait for all workers to complete ...
close(errC) // .. finally signal to caller we're truly done
}()
return errC
}
recurse logic:
- for any potentially blocking channel write, always check the
ctxfor cancelation, so we can abort early c.inis deliberately unbuffered to ensure delegation works (see final note)
func (c *Crawler) recurse(ctx context.Context, workID int, conn *net.Conn, wi workItem) error {
defer c.rwg.Done() // decrement recursion count
select {
case <-ctx.Done():
return ctx.Err() // canceled/timeout etc.
case c.out <- Result{ /* Item: wi.. */}: // write to results channel (manager or employee)
}
items, err := getItems(conn) // WORKER CODE (e.g. get manager employees etc.)
if err != nil {
return err
}
for _, i := range items {
// leaf case
if i.IsLeaf() {
select {
case <-ctx.Done():
return ctx.Err()
case c.out <- Result{ Item: i.Leaf }:
}
continue
}
// branch case
wi := workItem{
branch: i.Branch,
}
c.rwg.Add(1) // about to recurse (or delegate-recursion)
select {
case c.in <- wi:
// delegated to another worker!
case <-ctx.Done(): // context canceled...
c.rwg.Done() // ... so undo above `c.rwg.Add(1)`
return ctx.Err()
default:
// no-one to delegated to (all busy) - so this worker will keep working
err = c.recurse(ctx, workID, conn, wi)
if err != nil {
return err
}
}
}
return nil
}
Delegation is key:
- if a worker successfully writes to the worker channel, then it knows work has been delegated to another worker.
- if it cannot, then the worker knows all workers are busy working (i.e. not waiting on work items) - and so it must recurse itself
So one gets both the benefits of recursion, but also leveraging a fixed-sized worker pool.