SELECT * from dbfs:/FileStore/shared_uploads/prasanth/Company.csv
I am trying to select the records from folder in azure data bricks but I am facing this Error SQL statement: AnalysisException: Table or view not found
CodePudding user response:
Try it this way.
# in Python
flightData2015 = spark\
.read\
.option("inferSchema", "true")\
.option("header", "true")\
.csv("/data/flight-data/csv/2015-summary.csv")
// in Scala
import org.apache.spark.sql.types.{StructField, StructType, StringType, LongType}
val myManualSchema = new StructType(Array(
new StructField("DEST_COUNTRY_NAME", StringType, true),
new StructField("ORIGIN_COUNTRY_NAME", StringType, true),
new StructField("count", LongType, false)
))
spark.read.format("csv")
.option("header", "true")
.option("mode", "FAILFAST")
.schema(myManualSchema)
.load("/data/flight-data/csv/2010-summary.csv")
.show(5)
CodePudding user response:
I reproduced this got same error.

This error occurs when there is no table or view created earlier on that name in databricks SQL.
In the above, you are trying to query dbfs:/filepath.csv which is not a table or view in Databricks SQL.
To access dbfs file in databricks SQL, first we need to create a table or view for that and copy the csv file data into that. Then we can query that table.
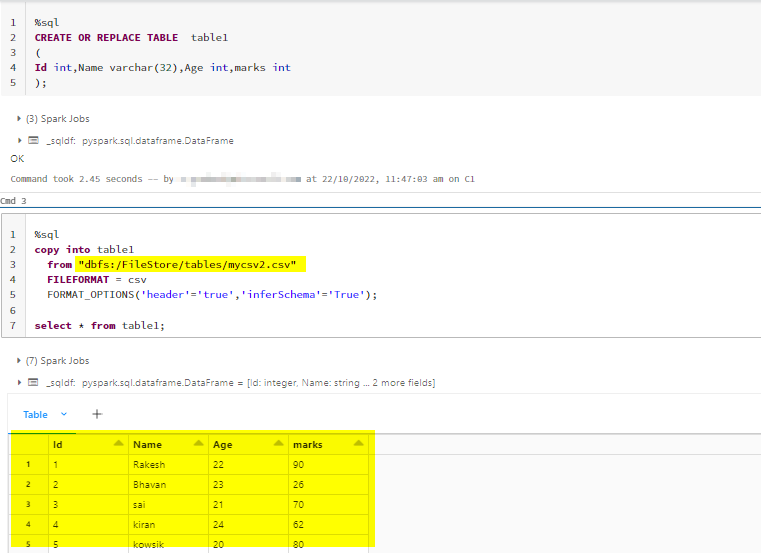
Code for that:
%sql
/*Table creation with schema*/
CREATE OR REPLACE TABLE table1
(
Id int,Name varchar(32),Age int,marks int
);
/*Copying dbfs csv data into table*/
copy into table1
from "dbfs:/FileStore/tables/mycsv2.csv"
FILEFORMAT = csv
FORMAT_OPTIONS('header'='true','inferSchema'='True');
select * from table1;
My Execution:
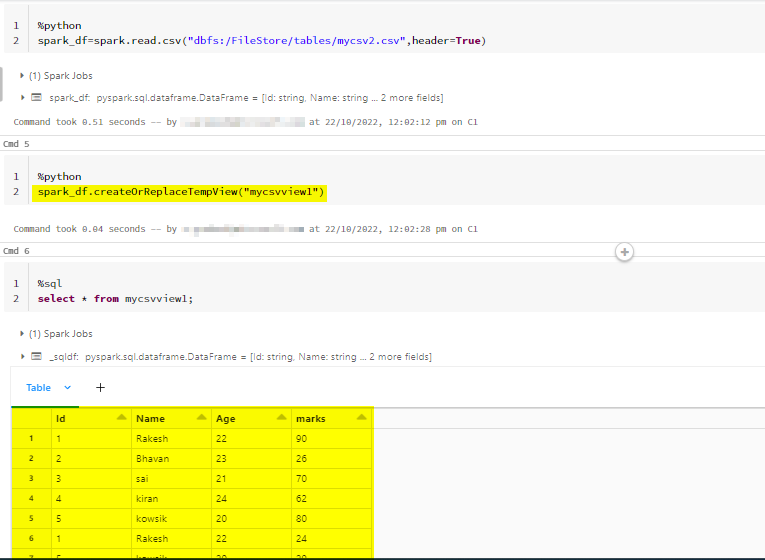
Another alternative(to query csv in databricks SQL) for this can be using pyspark or scala dataframe as suggested by @ASH above.
Read the csv file then create a temporary view.
Code:
%python
spark_df=spark.read.csv("dbfs:/FileStore/tables/mycsv2.csv",header=True)
#Creating temporary view for the dataframe.
spark_df.createOrReplaceTempView("mycsvview1")
%sql
select * from mycsvview1;
Output for your reference: