I have data like in the dataframe below. As you can see, there are columns "2019" and "2019_p", "2020" and "2020_p", "2021" and "2021_p".
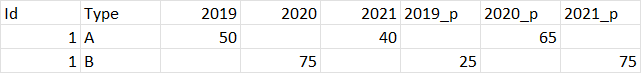
I want to select the final columns dynamically where if "2019" is null, take the value of "2019_p" and if the value of "2020" is null, take the value of "2020_p" and the same applies to "2021" etc.
I want to select the columns dynamically without hardcoding the column names. How do I achieve this?
I need output like this:
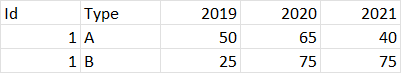
CodePudding user response:
Input:
from pyspark.sql import functions as F
df = spark.createDataFrame(
[(1, 'A', 50, None, 40, None, 65, None),
(1, 'B', None, 75, None, 25, None, 75)],
['Id', 'Type', '2019', '2020', '2021', '2019_p', '2020_p', '2021_p'])
One way could be this - using df.colRegex:
cols = list({c[:4] for c in df.columns if c not in ['Id', 'Type']})
df = df.select(
'Id', 'Type',
*[F.coalesce(*df.select(df.colRegex(f'`^{c}.*`')).columns).alias(c) for c in cols]
)
df.show()
# --- ---- ---- ---- ----
# | Id|Type|2020|2019|2021|
# --- ---- ---- ---- ----
# | 1| A| 65| 50| 40|
# | 1| B| 75| 25| 75|
# --- ---- ---- ---- ----
Also possible using startswith:
cols = list({c[:4] for c in df.columns if c not in ['Id', 'Type']})
df = df.select(
'Id', 'Type',
*[F.coalesce(*[x for x in df.columns if x.startswith(c)]).alias(c) for c in cols]
)
CodePudding user response:
you can simplify ZygD's approach to just use a list comprehension with coalesce (without regex).
# following list can be created from a source dataframe as well
year_cols = ['2019', '2020', '2021']
data_sdf. \
select('id', 'type',
*[func.coalesce(c, c '_p').alias(c) for c in year_cols]
). \
show()
# --- ---- ---- ---- ----
# | id|type|2019|2020|2021|
# --- ---- ---- ---- ----
# | 1| A| 50| 65| 40|
# | 1| B| 25| 75| 75|
# --- ---- ---- ---- ----
where the list comprehension would yield the following
[func.coalesce(c, c '_p').alias(c) for c in year_cols]
# [Column<'coalesce(2019, 2019_p) AS `2019`'>,
# Column<'coalesce(2020, 2020_p) AS `2020`'>,
# Column<'coalesce(2021, 2021_p) AS `2021`'>]