I need to get hrefs from <a> tags in a website, but not all, but only ones that are in the spans locted in the <div>s with classes arm
<html>
<body>
<div >
<span>
<a href="1">link</a>
<a href="2">link</a>
<a href="3">link</a>
</span>
</div>
<div >
<span>
<a href="4">link</a>
<a href="5">link</a>
<a href="6">link</a>
</span>
</div>
<div >
<span>
<a href="7">link</a>
<a href="8">link</a>
<a href="9">link</a>
</span>
</div>
<div >
<span>
<a href="1">anotherLink</a>
<a href="2">anotherLink</a>
<a href="3">anotherLink</a>
</span>
</div>
</body>
</html>
import requests
from bs4 import BeautifulSoup as bs
request = requests.get("url")
html = bs(request.content, 'html.parser')
for arm in html.select(".arm"):
anchor = arm.select("span > a")
print("anchor['href']")
But my code doesn't print anything
CodePudding user response:
Your code looks fine until you get to the print("anchor['href']") line which I assume is meant to be print(anchor['href']).
Now, anchor is a ResultSet, which means you will need another loop to get the hrefs. Here is how those final lines should look like if you want minimum modification to your code:
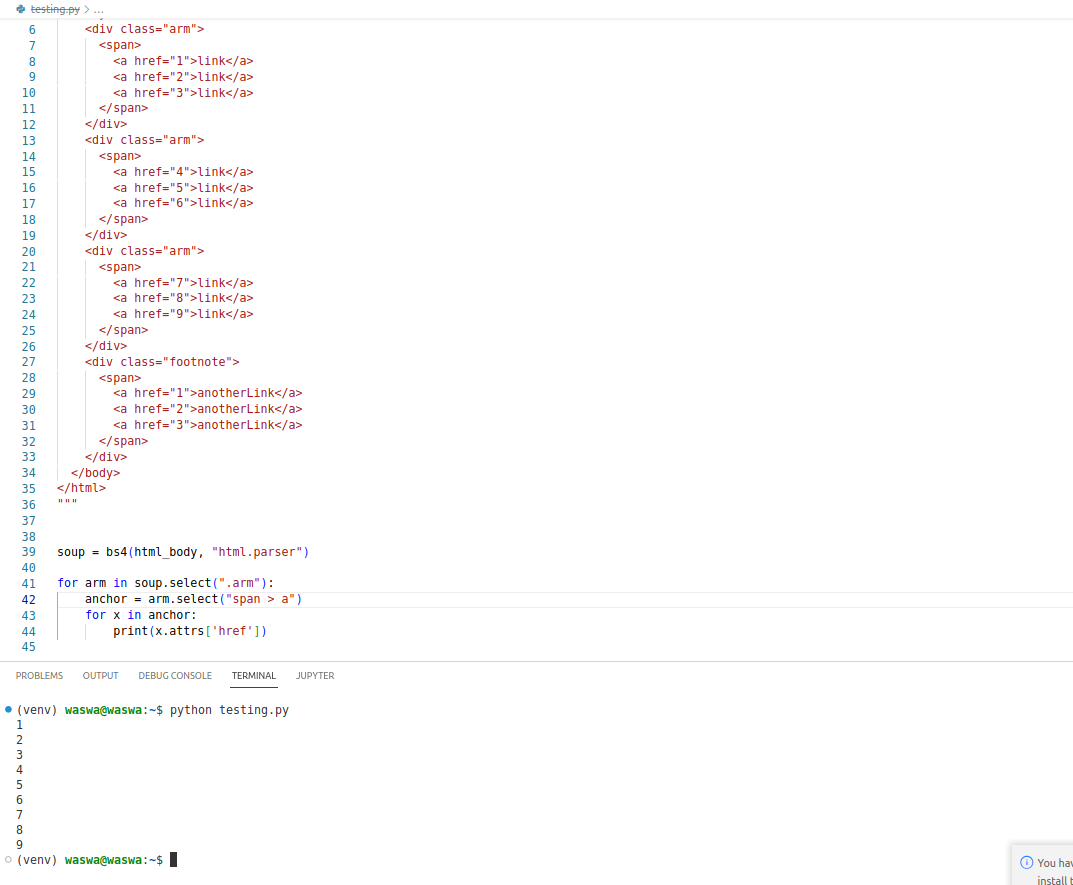
for arm in soup.select(".arm"):
anchor = arm.select("span > a")
for x in anchor:
print(x.attrs['href'])
We basically add:
for x in anchor:
print(x.attrs['href'])
And you should get the hrefs. All the best.
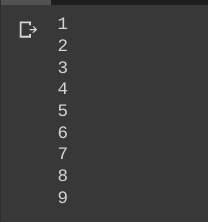
This is my output:
CodePudding user response:
Try using the find.all() method to obtain the values in a specific tags and class
I have replicated your HTML file and obtain the values in the span tag. Please see my sample code below.
Replicated HTML file:
# Creating the HTML file
file_html = open("demo.html", "w")
# Adding the input data to the HTML file
file_html.write('''<html>
<body>
<div >
<span>
<a href="1">link</a>
<a href="2">link</a>
<a href="3">link</a>
</span>
</div>
<div >
<span>
<a href="4">link</a>
<a href="5">link</a>
<a href="6">link</a>
</span>
</div>
<div >
<span>
<a href="7">link</a>
<a href="8">link</a>
<a href="9">link</a>
</span>
</div>
<div >
<span>
<a href="1">anotherLink</a>
<a href="2">anotherLink</a>
<a href="3">anotherLink</a>
</span>
</div>
</body>
</html>''')
# Saving the data into the HTML file
file_html.close()
code:
import requests
from bs4 import BeautifulSoup as bs
#reading the replicated html file
demo = open("demo.html", "r")
results = bs(demo, 'html.parser')
#Using find.all method to find specific tags and class
job_elements = results.find_all("div", class_="arm")
for job_element in job_elements:
links = job_element.find_all("a")
for link in links:
print(link['href'])
Output: