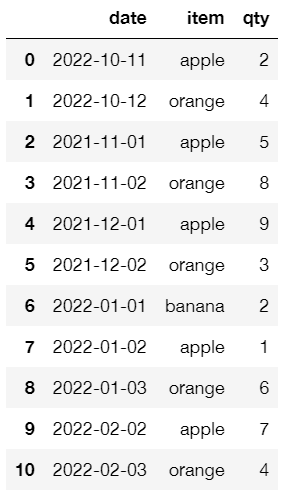
I have the following sample data
df = pd.DataFrame(columns=["date", "item", "qty"], data=[['2022-10-11','apple',2],['2022-10-12','orange',4],['2021-11-01','apple',5],['2021-11-02','orange',8],['2021-12-01','apple',9],['2021-12-02','orange',3],['2022-01-01','banana',2],['2022-01-02','apple',1],['2022-01-03','orange',6],['2022-02-02','apple',7],['2022-02-03','orange',4]])
df['date'] = pd.to_datetime(df['date'], format='%Y-%m-%d')
which looks like this
I would like to group rows into Years and Months, and items into columns, with row and column subtotals. Using an Excel pivot table, it would be done as so:
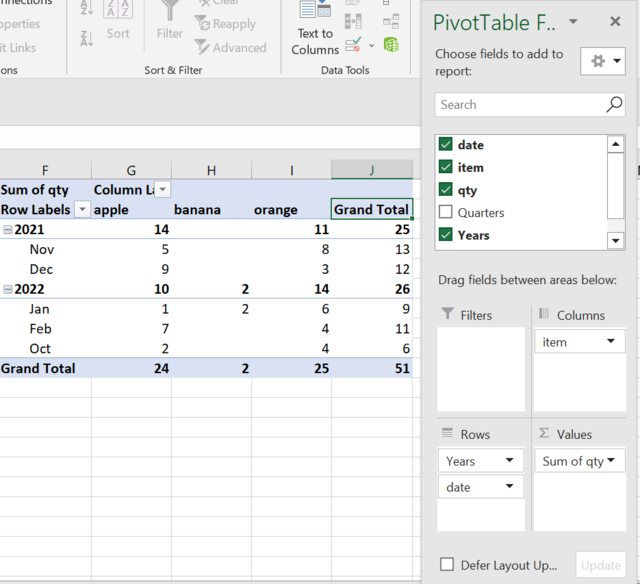
pd.pivot_table approach
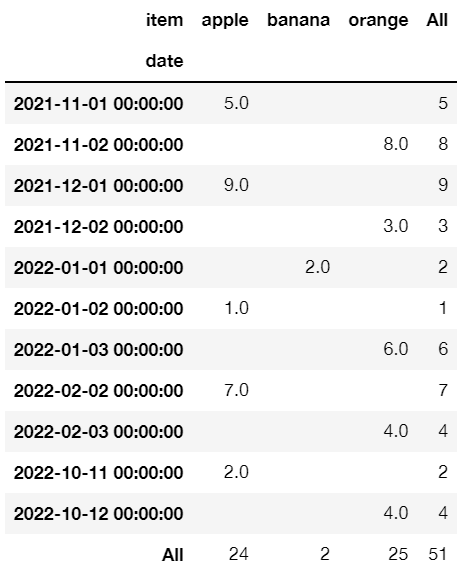
Now, using
pd.pivot_table(df, values='qty', index='date', columns='item', aggfunc='sum', fill_value='', margins=True)
I get something close but without the Year and Month row grouping:
If I replace index='date' by index=[pd.Grouper(key='date', freq='M')] I get an error:
KeyError: "[TimeGrouper(key='date', freq=<MonthEnd>, axis=0, sort=True, closed='right', label='right', how='mean', convention='e', origin='start_day')] not in index"
If I keep index=[pd.Grouper(key='date', freq='M')] but remove the margins=True, I get the pivot table but without the subtotals:
pd.pivot_table(df, values='qty', index=[pd.Grouper(key='date', freq='M')], columns='item', aggfunc='sum', fill_value=0) #removed margins=True
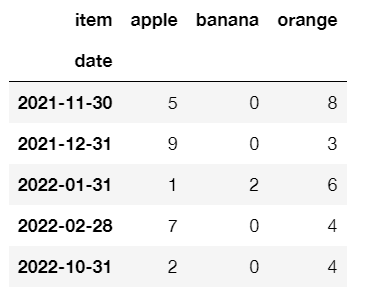
How can I have both the Year and Month groupings, and the subtotals?
groupby approach
As an alternative, I tried using groupby as follows. However the items show up as rows instead of columns, and I'm not sure how to get row (and column) subtotals.
df.groupby([df.date.dt.year, df.date.dt.month, 'item']).agg({'qty':'sum'})

CodePudding user response:
Use DataFrame.assign for helper columns year and month and pass to pivot_table:
(df.assign(year = df.date.dt.year,month = df.date.dt.month)
.pivot_table(values='qty',
index=['year','month'],
columns='item',
aggfunc='sum',
fill_value='',
margins=True))