I am trying to achieve this result: assign a category to a document based on its title, or part of its title.
| Title | Category |
|---|---|
| correspondence | Correspondence |
| Note Transmission Correspondence | Correspondence |
| Advisors Evaluation Report | Report |
| Country Notes | Correspondence |
| Annual Portfolio Report | Report |
| Appointment Letter | Correspondence |
The categories are arranged into a table (docCategories) where each row starts with a unique category name, and is followed by a set of labels that match entirely or partially with the document title.
| Category | Label | Label2 | Label3 | Label4 |
|---|---|---|---|---|
| Correspondence | Letter | Memo | Note | Correspondence |
| Report | Dashboard | Report |
The formula will take the document title and check if it matches any of the labels (with wild cards), so to return the unique category in the first position in the same row of the matched label.
Appointment Letter -> matches label:letter -> cat:Correspondence
I have made it working with this formula to be copied in the Category column:
=INDEX(docCategories;MIN(IF(docCategories=A2;ROW(docCategories)))-1;MIN(IF(docCategories=A2;1)))
And only if the title is exact matching of the entire label (e.g. Correspondence -> matches label:correspondence -> cat:Correspondence).
I am looking to have it working for matching on part of the title (e.g. Appointment Letter -> matches label:letter -> cat:Correspondence).
I have tried and failed to change the docCategories=<title> into something that can match the substring of the title, even applying the SPLITEXT(<title>) it still fails to give me the expected result.
Who can think of a creative solution for this?
CodePudding user response:
The following solution works for any number of categories and for any number of labels on any category. It also identifies if no labels were found and also if more than one label was found from a different category. Since the question doesn't specify any specific excel version tag I assume Microsoft Office 365 function can be used.
On cell I2 put the following formula:
=LET(rng, A2:E3, texts, G2:G9, lkupValues, B2:E3, categories, INDEX(rng,,1),
BYROW(texts, LAMBDA(text,LET(
reduceResult, REDUCE("",categories, LAMBDA(acc,c, LET(
lkup, XLOOKUP(c,categories, lkupValues), searchLabels, FILTER(lkup, lkup<>0),
IF(SUM(N(ISNUMBER(SEARCH(searchLabels,text))))=0, acc,
IF(acc="", c, "MORE THAN ONE CATEGORY FOUND"))
))), IF(reduceResult<>"", reduceResult, "CATEGORY NOT FOUND")
)))
)
and here is the corresponding output:
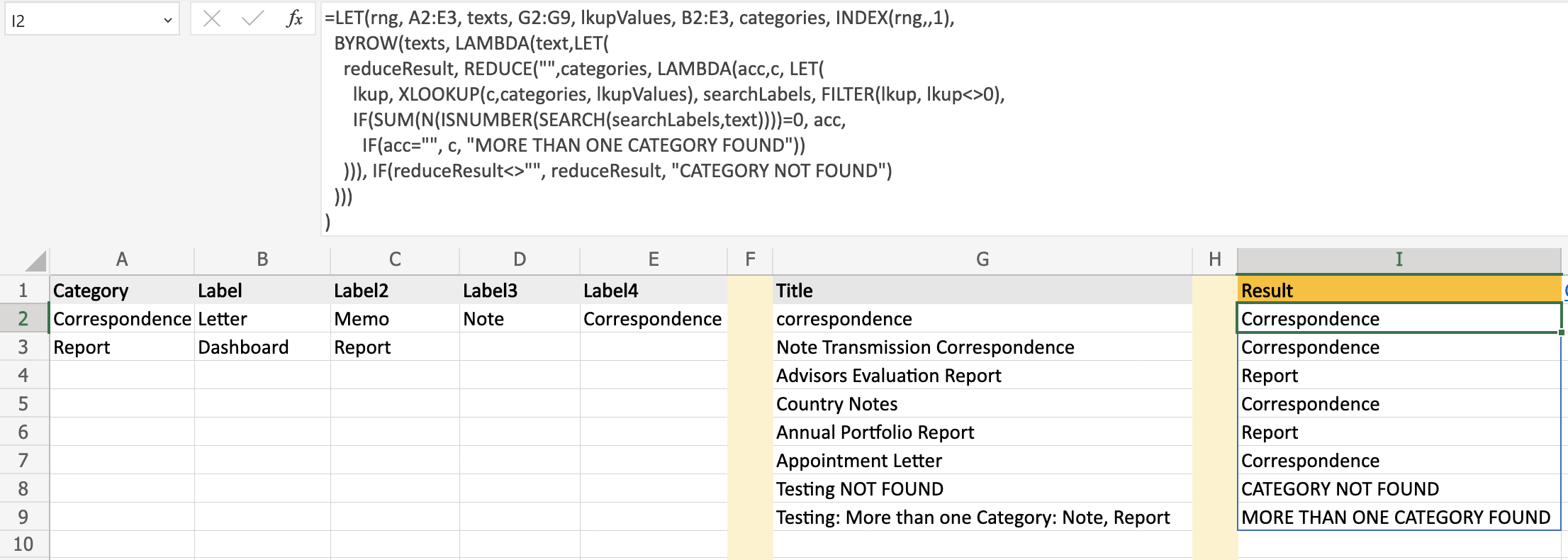
The last two rows Title column were added to test the Non-Happy paths.
Explanation
We use LET function to define the names to be used and to avoid repeating the same calculation. If in your excel version you have DROP function available, then the name: lkupValues can be defined as follow: DROP(rng,,1).
The main idea is to iterate over texts values via BYROW and for each text we invoke SEARCH function for all categories. When the first input argument of SEARCH is an array, it returns an array of the same shape indicating the start of the index position of the labels found in text or #VALUE! if no labels were found.
Note: SEARCH is not case sensitive, if that is not the case, then replace it with FIND.
We use REDUCE function to iterate over all categories to find a match. For each category (c) we find the corresponding labels via XLOOKUP. Since not all categories have the same number of labels, for example Report has fewer labels than the Correspondence category. We need to adjust it to remove empty labels. The name searchLabels filters the result to only non-empty labels.
For checking if labels were not found we use the following condition:
SUM(N(ISNUMBER(SEARCH(searchLabels,text))))=0
ISNUMBER converts the SEARCH result to TRUE/FALSE values. N function converts the result to equivalent 0,1 values.
If the condition is TRUE, it returns the accumulator (acc initialized to an empty string). If the condition is FALSE, some labels were found, then it returns the category (c) if acc is empty, i.e. no previous categories were found. If acc is not empty any previous category was found, so it returns MORE THAN ONE CATEGORY FOUND.
Finally, if the result of REDUCE (reduceResult) is an empty string, it means the accumulator was not updated after initialization, so no labels were found for any category and it is indicated with the output: CATEGORY NOT FOUND.