I'm looking to merge multiple data frames.
The main data frame consist of list of postal codes, and looks like so:
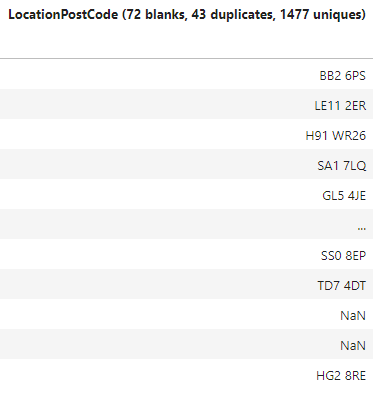
Then I have multiple csv files with all post codes with its areas, which named subsequently (area0.csv, area1.csv, and etc. up to area26.csv) and each file looks like so:
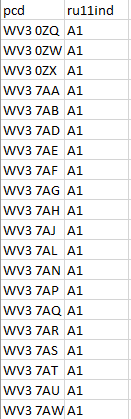
I'm aiming to build a new data frame that will consist area for each post code from data frame 1, and will look like so:
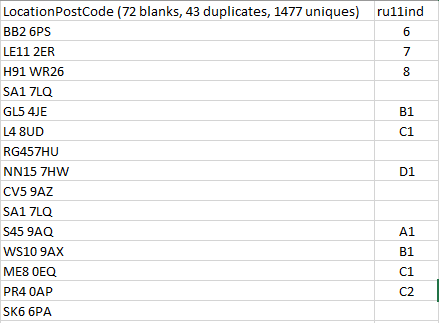
CodePudding user response:
Aren't you just looking for merge?
Example
maindf=pd.DataFrame({'LocationPostCode':['BB2 6PS', 'LE11 2ER', 'H91 WR26']})
csv1=pd.DataFrame({'pcd':['WV3 0ZQ', 'LE11 2ER'], 'ru11ind':['A1', 'A1']}) # I assume you know how to read a csv, but this dataframe is reproducible
csv2=pd.DataFrame({'pcd':['A21 CV51', 'H91 WR26'], 'ru11ind':['A2', 'A3']})
# At first we know no 'ru11ind'
maindf['ru11ind']=pd.NA
# Merge aka build a dataframe from maindf and csv1, such as LocationPostCode of one is pcd of other.
# The new dataframe will have 2 `ru11ind_x` and `ru11ind_y` columns, depending on where that `ru11ind` comes frome (from maindf or from csv1)
# With `how='left'` the new dataframe has the same rows as the old one, with `NA` in field `ru11ind_y` if a row of `maindf` matches no row of `csv1`
maindf=maindf.merge(csv1, left_on='LocationPostCode', right_on='pcd', how='left')
# Now maindf is
# LocationPostCode ru11ind_x pcd ru11ind_y
#0 BB2 6PS NaN NaN NaN
#1 LE11 2ER NaN LE11 2ER A1
#2 H91 WR26 NaN NaN NaN
# ru11ind_x is the column holding what ru11ind we knew before in maindf. Rename it
maindf.rename({'ru11ind_x':'ru11ind'}, axis=1, inplace=True)
# Now maindf is
# LocationPostCode ru11ind pcd ru11ind_y
#0 BB2 6PS NaN NaN NaN
#1 LE11 2ER NaN LE11 2ER A1
#2 H91 WR26 NaN NaN NaN
# What are the rows for which we learned something new?
f=maindf['ru11ind'].isna() & ~(maindf['ru11ind_y'].isna())
# For those rows, we copy `ru11ind_y` (the `ru11ind` from csv1) to `ru11ind` column
maindf.loc[f, 'ru11ind']=maindf[f]['ru11ind_y']
# Now maindf is
# LocationPostCode ru11ind pcd ru11ind_y
#0 BB2 6PS NaN NaN NaN
#1 LE11 2ER A1 LE11 2ER A1
#2 H91 WR26 NaN NaN NaN
# We don't need neither `pcd` columns (which is just identical to LocationPostCode where it exists), nor `ru11ind_y`, from which we've copied anything interesting in `ru11ind`
maindf.drop(columns=['pcd', 'ru11ind_y'], inplace=True)
# Now maindf is
# LocationPostCode ru11ind
#0 BB2 6PS NaN
#1 LE11 2ER A1
#2 H91 WR26 NaN
# Let's redo that with csv2
maindf=maindf.merge(csv2, left_on='LocationPostCode', right_on='pcd', how='left')
# LocationPostCode ru11ind_x pcd ru11ind_y
#0 BB2 6PS NaN NaN NaN
#1 LE11 2ER A1 NaN NaN
#2 H91 WR26 NaN H91 WR26 A3
maindf.rename({'ru11ind_x':'ru11ind'}, axis=1, inplace=True)
# LocationPostCode ru11ind pcd ru11ind_y
#0 BB2 6PS NaN NaN NaN
#1 LE11 2ER A1 NaN NaN
#2 H91 WR26 NaN H91 WR26 A3
f=maindf['ru11ind'].isna() & ~(maindf['ru11ind_y'].isna())
maindf.loc[f, 'ru11ind']=maindf[f]['ru11ind_y']
# LocationPostCode ru11ind pcd ru11ind_y
#0 BB2 6PS NaN NaN NaN
#1 LE11 2ER A1 NaN NaN
#2 H91 WR26 A3 H91 WR26 A3
maindf.drop(columns=['pcd', 'ru11ind_y'], inplace=True)
# LocationPostCode ru11ind
#0 BB2 6PS NaN
#1 LE11 2ER A1
#2 H91 WR26 A3
Obvioulsy, the first csv could be dealt with differently, since there is nothing interesting at first in ru11ind (so we could just merge without a ru11ind column, and that would create a brand new one with either NA or what is in csv1)
But the idea, clearly, is that this should be done iteratively over all csv. So, it is easier if we don't need to process the first csv differently to the others. In other words, my initial maindf['ru11ind']=pd.NA is what is called a sentinel (a dummy variable whose unique raison d'être is to ensure that first loop is not different than the other).
I let the rest (how to get content of csv, which are not part of the question, and how to do that iteratively) to you
CodePudding user response:
Here is where I got to:
# reading 'locations' file
df_loc = pd.read_excel('C:/Users/User/Desktop/Lloyds Pharma/locations.xlsx')
# saving results location
results_loc = 'C:/Users/User/Desktop/Lloyds Pharma/tmp_chunks/'
# OS folder path to chunck files for national statistics dataset
dir_path = r'C:\\Users\\User\\Desktop\\Lloyds Pharma\\tmp_chunks\\'
# list to store chunck files for national statistics dataset
files_list = []
# iterate directory
for path in os.listdir(dir_path):
# check if current path is a file
if os.path.isfile(os.path.join(dir_path, path)):
files_list.append(path)
df_loc.to_csv(results_loc 'res.csv', index=False)
for i in files_list:
res = pd.read_csv(results_loc 'res.csv')
df = pd.read_csv(results_loc i)
inner_join = pd.merge(res,
df[['pcd','ru11ind']],
left_on ='LocationPostCode (72 blanks, 43 duplicates, 1477 uniques)',
right_on ='pcd',
how ='left')
inner_join.to_csv(results_loc 'res.csv', index=False)
But as expected, this results into multiple pcd's and ru11ind's, and looks like this:
{kind=link}
How do I get all results in a single pcd, ru11ind columns? Obviously, pcd can be dropped as it is not required.