I have dataset like this below.
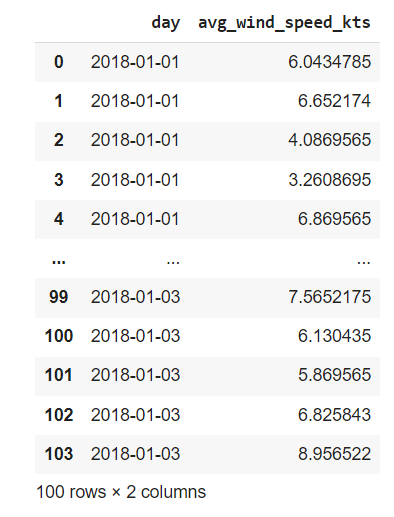
What i want to do is I want to groupby the data based on date column but do not want aggregation on avg_wind_speed_kts column, instead, i want all the values in avg_wind_speed_kts for one particular date to be added as new columns. Like below for example
| | date | s1 | s2 | s3 | ...... | s38 | s39 |
|:---- |:------:| -----:|
| 0 | 2018-01-01 | 6.0434785| 6.652174 | 4.0869565 | 3.2608695 | ... | 5.9130435 | 6.5876436 |
| 1 | 2018-01-02 | 6.652174 | 3.2608695| 5.5652175| 5.9130435 | .... |6.652174 | 4.0869565 |
I am not able to figure out how can this be done. Any help would be appreciated. Thanks
CodePudding user response:
Sample data:
df=pd.DataFrame(data={'day':['2018-01-01','2018-01-01','2018-01-01','2018-01-01','2018-01-02','2018-01-02','2018-01-02','2018-01-02'],'avg_wind_speed_kts':[6.0434785,6.652174,4.0869565,3.2608695,6.652174,3.2608695,5.5652175,5.9130435]})
df
day avg_wind_speed_kts
0 2018-01-01 6.0434785
1 2018-01-01 6.652174
2 2018-01-01 4.0869565
3 2018-01-01 3.2608695
4 2018-01-02 6.652174
5 2018-01-02 3.2608695
6 2018-01-02 5.5652175
7 2018-01-02 5.9130435
First, groupby day and keep the item of each group in a list.
dfx=df.groupby('day').agg({'avg_wind_speed_kts':list})
print(dfx)
day avg_wind_speed_kts
2018-01-01 [6.0434785, 6.652174, 4.0869565, 3.2608695]
2018-01-02 [6.652174, 3.2608695, 5.5652175, 5.9130435]
Then split list to new columns.
final = pd.DataFrame(dfx['avg_wind_speed_kts'].tolist(),index=dfx.index).add_prefix("s")
print(final)
day s0 s1 s2 s3
2018-01-01 6.0434785 6.652174 4.0869565 3.2608695
2018-01-02 6.652174 3.2608695 5.5652175 5.9130435