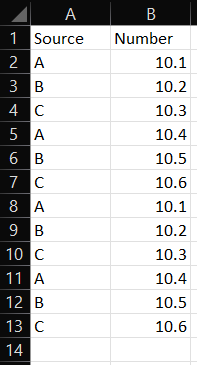
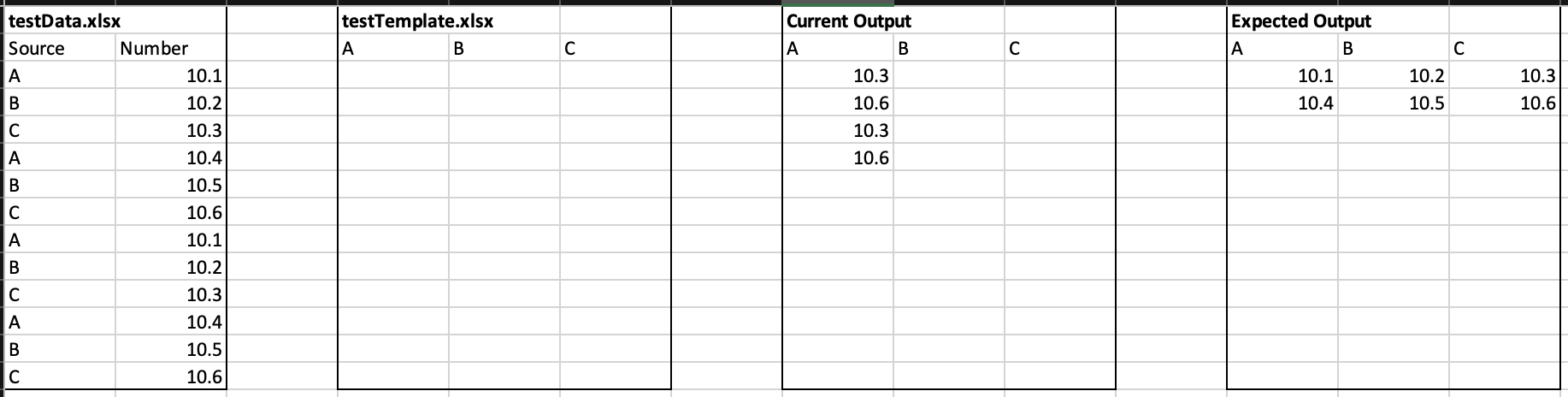
My script copies from one workbook to another and sorts them based on value. I'm trying to find a way to remove duplicates. I tried to use an if statement to check if the data already exists in the destination workbook, but it is not working correctly. Where am I going wrong?
from openpyxl import load_workbook
from openpyxl import Workbook
wb = load_workbook('testData.xlsx')
wb2 = load_workbook('testTemplate.xlsx')
ws = wb.worksheets[0]
mr = ws.max_row
ws2 = wb2.worksheets[0]
A = ws2.max_row
B = ws2.max_row
C = ws2.max_row
ws2values = set()
for row in ws.iter_rows(min_row = 2, min_col = 1, max_row = mr, max_col = 2):
for cell in row:
if cell.value == "A":
if ws2.cell(row = A 1, column = 1).value in ws2values:
pass
else:
ws2.cell(row = A 1, column = 1).value = (cell.offset(column = 1).value)
A = 1
elif cell.value == "B":
if ws2.cell(row = B 1, column = 1).value in ws2values:
pass
else:
ws2.cell(row = B 1, column = 1).value = (cell.offset(column = 1).value)
B = 1
elif cell.value == "C":
if ws2.cell(row = C 1, column = 1).value in ws2values:
pass
else:
ws2.cell(row = C 1, column = 1).value = (cell.offset(column = 1).value)
C = 1
wb2.save('testTemplate.xlsx')
CodePudding user response:
I don't see the pandas tag in your question but in case you're interested, you can use some of this library functions to avoid loops, speed up your transformation and get the same result you're looking for.
import pandas as pd
cols_template= ["A", "B", "C"]
def concat_missingvals(df):
out = pd.concat([df, pd.DataFrame(index=range(0, len(df)), columns=cols_template)],
ignore_index=True).dropna(how="all")
return out
df = (
pd.read_excel("testData.xlsx",
usecols=["Source", "Number"])
.drop_duplicates()
.assign(idx= lambda x: x.groupby("Source").cumcount())
.pivot(index="Source", columns="idx")
.transpose()
.reset_index(drop=True)
.rename_axis(None, axis=1)
.pipe(concat_missingvals)
)
# Output :
print(df)
A B C
0 10.1 10.2 10.3
1 10.4 10.5 10.6
You can then use