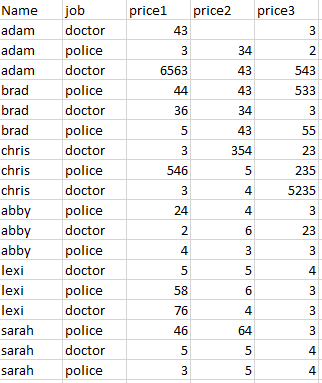
df <- data.frame (Name = c("adam", "adam", "adam", "brad", "brad", "brad", "chris", "chris", "chris", "abby", "abby", "abby", "lexi", "lexi", "lexi", "sarah", "sarah", "sarah"),
job = c("doctor", "police", "doctor", "police", "doctor", "police", "doctor", "police", "doctor", "police", "doctor", "police", "doctor", "police", "doctor", "police", "doctor", "police"),
price1 = c(43, 3, 6563, 44, 36, 5, 3, 546, 3, 24, 2, 4, 5, 58, 76, 46, 5, 3),
price2 = c(0, 34, 43, 43, 34, 43, 354, 5, 4, 4, 6, 3, 5, 6, 4, 64, 5, 5),
price3 = c(3, 2, 543, 533, 3, 55, 23, 235, 5235, 3, 23, 3, 4, 3, 3, 3, 4, 4)
)
> df
Name job price1 price2 price3
1 adam doctor 43 0 3
2 adam police 3 34 2
3 adam doctor 6563 43 543
4 brad police 44 43 533
5 brad doctor 36 34 3
6 brad police 5 43 55
7 chris doctor 3 354 23
8 chris police 546 5 235
9 chris doctor 3 4 5235
10 abby police 24 4 3
11 abby doctor 2 6 23
12 abby police 4 3 3
13 lexi doctor 5 5 4
14 lexi police 58 6 3
15 lexi doctor 76 4 3
16 sarah police 46 64 3
17 sarah doctor 5 5 4
18 sarah police 3 5 4
I am looking for an efficient way in R where i can get the correlation between the prices grouped by Name and job.
For example: I would like to get the correlation of price 1 and price 2 grouped by Name and job.
When I do cor(DF) it returns the correlation of all the prices but not grouped by the name and job, how would I go about doing this?
Thanks!
CodePudding user response:
Solutions using both data.table and dplyr
dt = data.table(name = c("adam", "adam", "richard", "adam"),
job = c("doctor", "police", "doctor", "police"),
price1 = c(43, 50, 30, 40),
price2 = c(0, 30, 10, 50),
price3 = c(1, 20, 20, 20))
dt[, cor(price1, price2), by = .(name, job)]
tibble(dt) |>
group_by(name, job) |>
summarise(correlation = cor(price1, price2))