import numpy as np
import pandas as pd
data = { 'ID': [112,113],'empDetails':[[{'key': 'score', 'value': 2},{'key': 'Name', 'value': 'Ajay'}, {'key': 'Department', 'value': 'HR'}],[ {'key': 'salary', 'value': 7.5},{'key': 'Name', 'value': 'Balu'}]]}
dataDF = pd.DataFrame(data)
#trails
# dataDF['newColumns'] = dataDF['empDetails'].apply(lambda x: x[0].get('key'))
# dataDF = dataDF['empDetails'].apply(pd.Series)
# create dataframe
# dataDF = pd.DataFrame(dataDF['empDetails'], columns=dataDF['empDetails'].keys())
# create the dataframe
# df = pd.concat([pd.DataFrame(v, columns=[k]) for k, v in dataDF['empDetails'].items()], axis=1)
# print(dataDF['empDetails'].items())
display(dataDF)
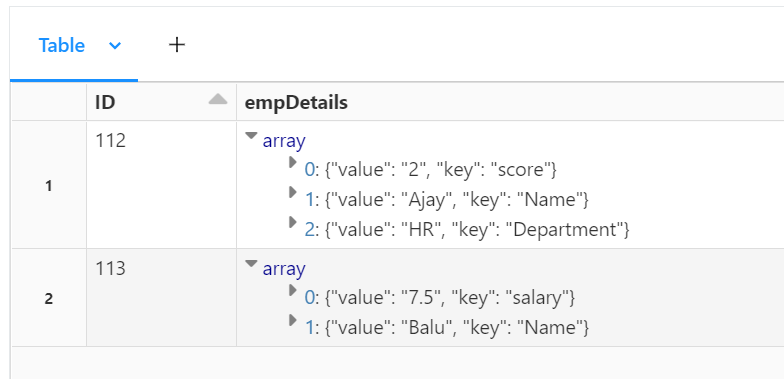 I am trying to iterate through empDetails column and fetch the value of Name,salary and Department into 3 different column
I am trying to iterate through empDetails column and fetch the value of Name,salary and Department into 3 different column
Using pd.series I am able to split the dictionary into different columns, but not able to rename the columns as the column order may change.
What will be the effective way to do this.
Expected output

CodePudding user response:
Use lambda function for extract keys and values to new dictionaries and pass to DataFrame constructor:
f = lambda x: {y['key']:y['value'] for y in x}
df = dataDF.join(pd.DataFrame(dataDF['empDetails'].apply(f).tolist(), index=dataDF.index))
print (df)
ID empDetails score Name \
0 112 [{'key': 'score', 'value': 2}, {'key': 'Name',... 2.0 Ajay
1 113 [{'key': 'salary', 'value': 7.5}, {'key': 'Nam... NaN Balu
Department salary
0 HR NaN
1 NaN 7.5
Alternative solution:
f = lambda x: pd.Series({y['key']:y['value'] for y in x})
df = dataDF.join(dataDF['empDetails'].apply(f))
print (df)
ID empDetails score Name \
0 112 [{'key': 'score', 'value': 2}, {'key': 'Name',... 2.0 Ajay
1 113 [{'key': 'salary', 'value': 7.5}, {'key': 'Nam... NaN Balu
Department salary
0 HR NaN
1 NaN 7.5
Or use list comprehension (only pandas solution):
df1 = pd.DataFrame([{y['key']:y['value'] for y in x} for x in dataDF['empDetails']],
index=dataDF.index)
df = dataDF.join(df1)
CodePudding user response:
If you are using python 3.5 , then you can unroll dict elements and append "ID" column in one line:
df.apply(lambda row: pd.Series({**{"ID":row["ID"]}, **{ed["key"]:ed["value"] for ed in row["empDetails"]}}), axis=1)
Update: If you want all columns from original df, then use dict comprehension:
df.apply(lambda row: pd.Series({**{col:row[col] for col in df.columns}, **{ed["key"]:ed["value"] for ed in row["empDetails"]}}), axis=1)
Full example:
data = { 'ID': [112,113],'empDetails':[[{'key': 'score', 'value': 2},{'key': 'Name', 'value': 'Ajay'}, {'key': 'Department', 'value': 'HR'}],[ {'key': 'salary', 'value': 7.5},{'key': 'Name', 'value': 'Balu'}]]}
df = pd.DataFrame(data)
df = df.apply(lambda row: pd.Series({**{col:row[col] for col in df.columns}, **{ed["key"]:ed["value"] for ed in row["empDetails"]}}), axis=1)
[Out]:
Department ID Name salary score
0 HR 112 Ajay NaN 2.0
1 NaN 113 Balu 7.5 NaN