I have a dataframe, the first column contains string (eg:'AABCD'). I have to count occurences for each string. Then the results for each count must be stored in column (one column for each character, A,B,C,D). See below
I have the following dataframe:
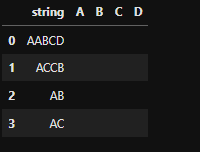
I want to get:
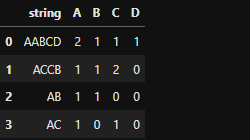
Remark: Columns A, B, C, D contain the number of characters for each string in each line
I want to create columns A,B,C,D with the number of characters for each string in each line
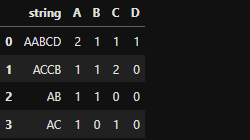
CodePudding user response:
Assuming the columns are already in the dataframe, and the column containing the strings to start really is a column and not the index:
Set up dataframe:
df = pd.DataFrame({
"string":["AABCD", "ACCB", "AB", "AC"],
"A":[float("nan"),float("nan"),float("nan"),float("nan")],
"B":[float("nan"),float("nan"),float("nan"),float("nan")],
"C":[float("nan"),float("nan"),float("nan"),float("nan")],
"D":[float("nan"),float("nan"),float("nan"),float("nan")],
})
Loop through the columns and apply a lambda function to each row.
for col_name in df.columns:
if col_name == "string":
continue
df[col_name]=df.apply(lambda row: row["string"].count(col_name), axis=1)