Hi I am trying to train a tensorflow convolutional model on a small portion of the kaggle dogs-vs-cats dataset.
I am building the model in the following way:
from tensorflow import keras
from tensorflow.keras import layers
from tensorflow.keras.utils import image_dataset_from_directory
import pathlib
new_base_dir = pathlib.Path("../8/cats_vs_dogs_small")
data_augmentation = keras.Sequential(
[
layers.RandomFlip("horizontal"),
layers.RandomRotation(0.1),
layers.RandomZoom(0.2),
]
)
inputs = keras.Input(shape=(180, 180, 3))
x = data_augmentation(inputs)
x = layers.Rescaling(1./255)(x)
x = layers.Conv2D(filters=32, kernel_size=3, activation="relu")(x)
x = layers.MaxPooling2D(pool_size=2)(x)
x = layers.Conv2D(filters=64, kernel_size=3, activation="relu")(x)
x = layers.MaxPooling2D(pool_size=2)(x)
x = layers.Conv2D(filters=128, kernel_size=3, activation="relu")(x)
x = layers.MaxPooling2D(pool_size=2)(x)
x = layers.Conv2D(filters=256, kernel_size=3, activation="relu")(x)
x = layers.MaxPooling2D(pool_size=2)(x)
x = layers.Conv2D(filters=256, kernel_size=3, activation="relu")(x)
x = layers.Flatten()(x)
x = layers.Dropout(0.5)(x)
outputs = layers.Dense(1, activation="sigmoid")(x)
model = keras.Model(inputs=inputs, outputs=outputs)
train_dataset = image_dataset_from_directory(
new_base_dir/"train",
image_size=(180,180),
batch_size=32
)
validation_dataset = image_dataset_from_directory(
new_base_dir/"validation",
image_size=(180,180),
batch_size=32
)
test_dataset = image_dataset_from_directory(
new_base_dir/"test",
image_size=(180,180),
batch_size=32
)
and I tried to compile in two ways, that I expected to the same:
model.compile(optimizer=keras.optimizers.RMSprop(),
loss=keras.losses.BinaryCrossentropy(),
metrics=[keras.metrics.Accuracy()])
and
model.compile(loss="binary_crossentropy",
optimizer="rmsprop",
metrics=["accuracy"])
and then training with
history = model.fit(
train_dataset,
validation_data=validation_dataset,
epochs=5)
However, I am getting different results in the two compilations. In the first case the model does not seem to train at all (see first figure). Whereas in the second case, the model is learning (see second figure).
Is there any difference between the two compilations? Why?
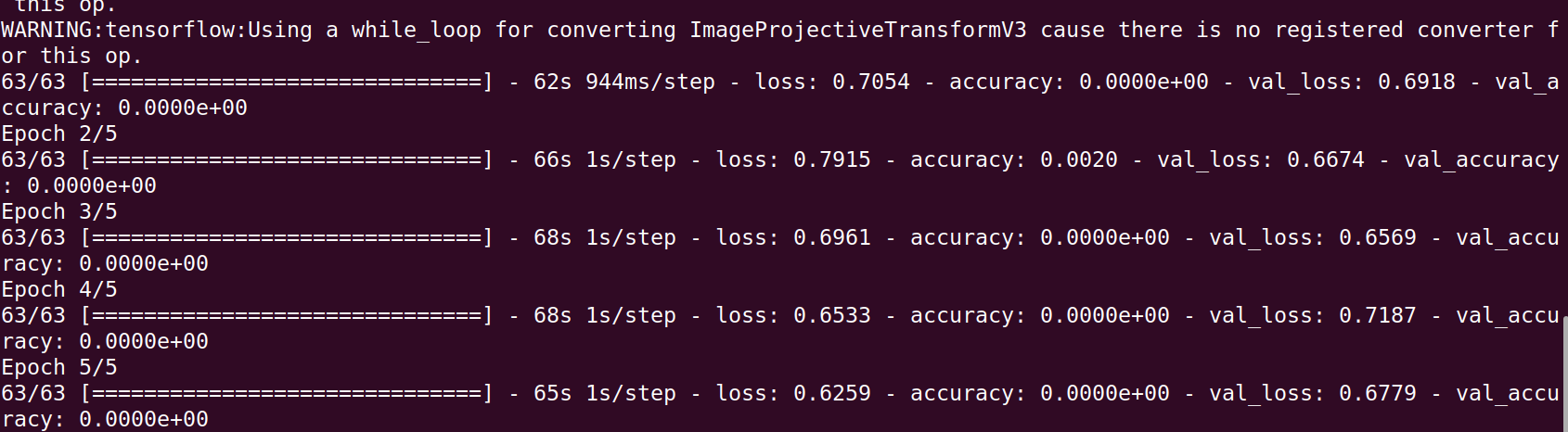
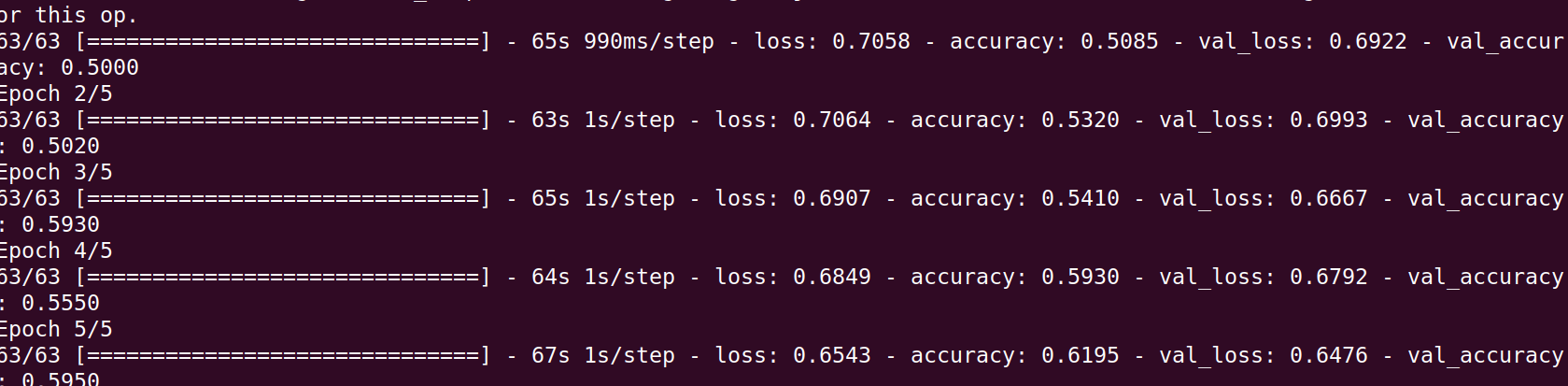
Getting the dataset To get the dataset and use a smaller version if you have a kaggle account you can do
!kaggle competitions download -c dogs-vs-cats
!unzip -qq train.zip
(if from a terminal and not from a Jupyter notebook remove the !) and to get a smaller version of the dataset, you can use the following script
import os, shutil, pathlib
original_dir = pathlib.Path("./train")
new_base_dir = pathlib.Path("cats_vs_dogs_small")
def make_subset(subset_name, start_index, end_index):
for category in ("cat", "dog"):
dir = new_base_dir / subset_name / category
os.makedirs(dir)
fnames = [f"{category}.{i}.jpg" for i in range(start_index, end_index)]
for fname in fnames:
shutil.copyfile(src=original_dir / fname,
dst=dir / fname)
make_subset("train", start_index=0, end_index=1000)
make_subset("validation", start_index=1000, end_index=1500)
make_subset("test", start_index=1500, end_index=2500)
The example is taken from here
CodePudding user response:
It is because the string "accuracy" is converted to tf.keras.metrics.BinaryAccuracy() (which turns a float into 0-1 automatically with 0.5 as the threshold) under the hood. In your first case, you are using tf.keras.metrics.Accuracy() which requires exact match while your model only outputs a float number probability instead of 0-1.
See the official documentation:
When you pass the strings 'accuracy' or 'acc', we convert this to one of tf.keras.metrics.BinaryAccuracy, tf.keras.metrics.CategoricalAccuracy, tf.keras.metrics.SparseCategoricalAccuracy based on the loss function used and the model output shape.