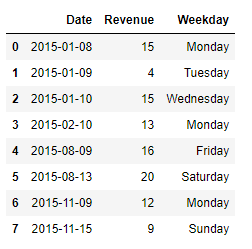
The dataframe contains date column, revenue column(for specific date) and the name of the day.
This is the code for creating the df:
pd.DataFrame({'Date':['2015-01-08','2015-01-09','2015-01-10','2015-02-10','2015-08-09','2015-08-13','2015-11-09','2015-11-15'],
'Revenue':[15,4,15,13,16,20,12,9],
'Weekday':['Monday','Tuesday','Wednesday','Monday','Friday','Saturday','Monday','Sunday']})
I want to find the sum of revenue between Mondays:
2015-02-10 34 Monday
2015-11-09 49 Monday etc.
CodePudding user response:
First idea is used Weekday for groups by compare by Monday with cumulative sum and aggregate per groups:
df1 = (df.groupby(df['Weekday'].eq('Monday').cumsum())
.agg({'Date':'first','Revenue':'sum', 'Weekday':'first'}))
print (df1)
Date Revenue Weekday
Weekday
1 2015-01-08 34 Monday
2 2015-02-10 49 Monday
3 2015-11-09 21 Monday
But seems not matched Weekday column with Dates in sample data, so DataFrame.resample per weeks starting by Mondays return different output:
df['Date'] = pd.to_datetime(df['Date'])
df2 = df.resample('W-Mon', on='Date').agg({'Revenue':'sum', 'Weekday':'first'}).dropna()
print (df2)
Revenue Weekday
Date
2015-01-12 34 Monday
2015-02-16 13 Monday
2015-08-10 16 Friday
2015-08-17 20 Saturday
2015-11-09 12 Monday
2015-11-16 9 Sunday
CodePudding user response:
First convert your Date column from string to datetime type:
df.Date = pd.to_datetime(df.Date)
Then generate the result:
result = df.groupby(pd.Grouper(key='Date', freq='W-MON', label='left')).Revenue.sum()/
.reset_index()
This result does not contain day of week and in my opinion this is OK, as they will be all Mondays.
If you want to see only weeks with non-zero result, you can get it as:
result[result.Revenue != 0]
For your source data the result is:
Date Revenue
0 2015-01-05 34
5 2015-02-09 13
30 2015-08-03 16
31 2015-08-10 20
43 2015-11-02 12
44 2015-11-09 9
CodePudding user response:
happy with what
feelings
heart
you have
- no regrets
- no crying
- smiling face