I have a sample dataframe:
| ID | SampleColumn1| SampleColumn2 | SampleColumn3 | SampleColumn4 |
|:-- |:------------:| ------------ :| ------------ | ------------ |
| 1 |sample Apple | sample Cherry | sample Lime | sample Apple |
| 2 |sample Cherry | sample lemon | sample Grape | sample Cherry |
I would like to create a new DataFrame based off of this initial dataframe. Should one of several values in a list [Apple, Lime, Cherry, Guava, Pear] be in any of the columns for a row, it would appear as a 1 in the new dataframe for its column. I do not wish to get the frequency, just if one of the values of the values from the list are in the dataframe row, then it should be a 1, else it will be a 0. In this case, the output should be:
| ID | Apple | Lime | Cherry | Guava | Pear |
| 1 | 1 | 1 | 1 | 0 | 0 |
| 2 | 0 | 0 | 1 | 0 | 0 |
Currently I have tried in going about in initially establishing the dataframe by creating the columns based off the list mentioned before (list=[Apple, Lime, Cherry, Guava, Pear]) and then using the find function for a string, transforming a series into a string for each row then using an if condition if the value has returned and equals the column name of the new dataframe. I am getting a logic error in this regard.
CodePudding user response:
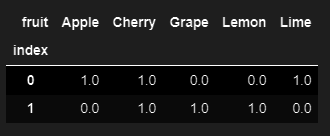
You can do it using stack() and pivot_table()
import pandas as pd
df = pd.DataFrame([['Apple','Lime','Cherry','Apple'],['Cherry','Lemon','Grape','Cherry']])
df_stack = pd.DataFrame(df.stack()).droplevel(1).reset_index().rename(columns={0:'fruit'})
df_stack['values'] = 1
df_stack.pivot_table(index = 'index',columns=['fruit'], values='values').fillna(0)
OP:
CodePudding user response:
Use get_dummies with aggregate max:
f = lambda x: x.replace('sample ','')
df = (pd.get_dummies(df.set_index('ID'), prefix='', prefix_sep='').rename(columns=f)
.groupby(level=0, axis=1).max())
print (df)
Apple Cherry Grape Lime lemon
ID
1 1 1 0 1 0
2 0 1 1 0 1