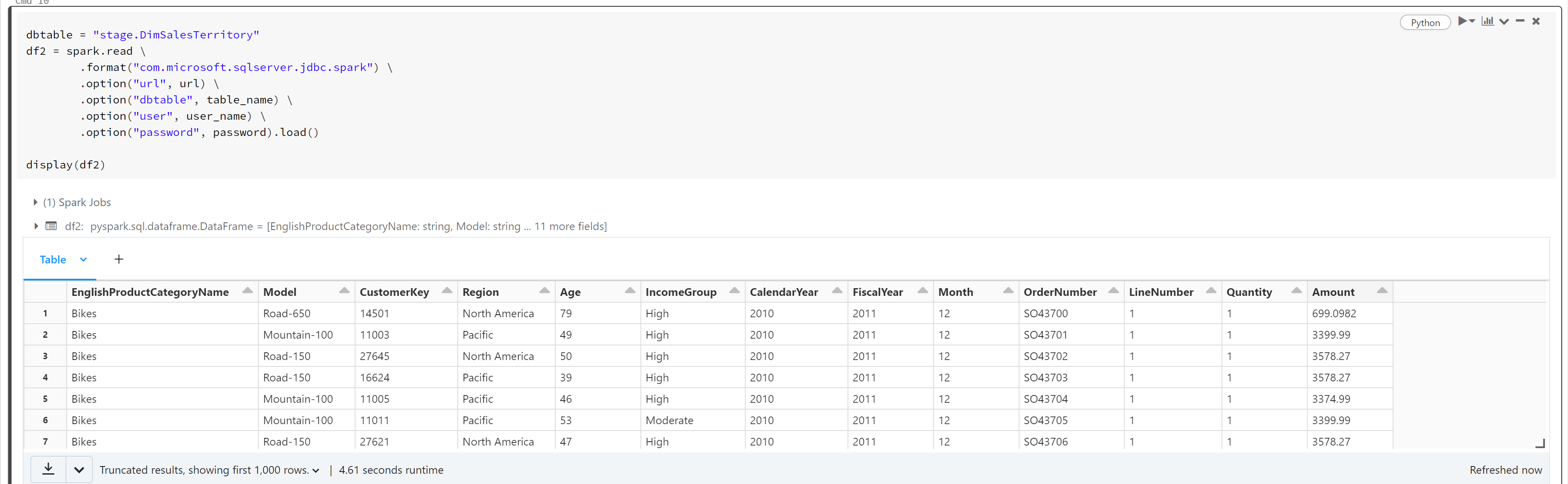
Quickly, my need: create a Spark dataframe from a more or less complex query in T-SQL (SQL Server) and/or from the output of a SQL Server stored procedure.
As far I understand, Spark does not allow to execute queries in the dialect of the underlying data source. Yes, there is 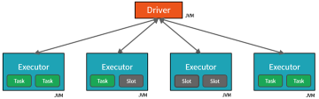
It is better to use a spark driver for JDBC. Microsoft has one.
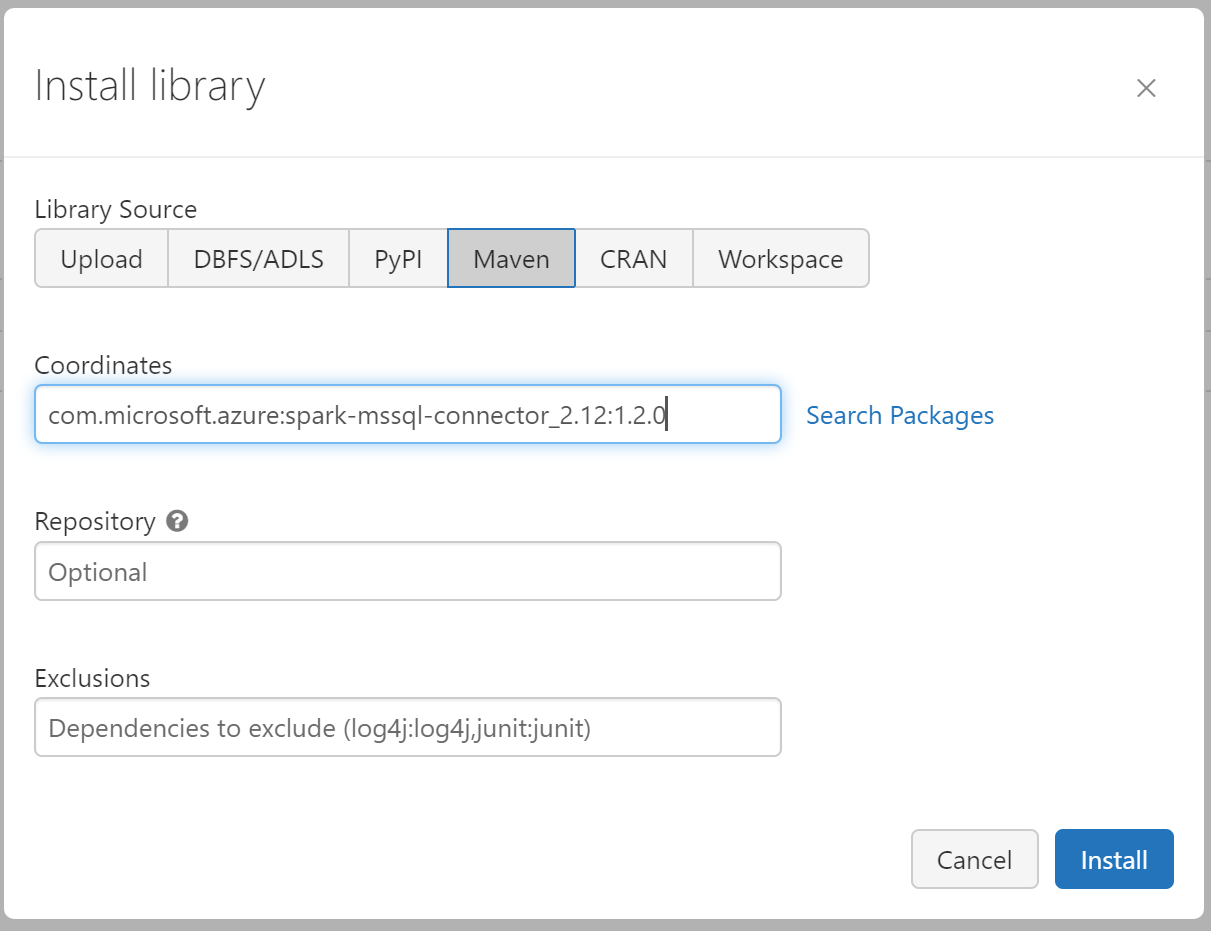
I am using Spark Version > 3.1.
I have the adventure works database with a view called v.
#
# Set connection properties
#
server_name = "jdbc:sqlserver://svr4tips2030.database.windows.net"
database_name = "dbs4advwrks"
url = server_name ";" "databaseName=" database_name ";"
table_name = "dbo.vDMPrep"
user_name = "enter your user here"
password = "enter your password here"
Make a typical spark.read() call with the JDBC driver.
df = spark.read \
.format("com.microsoft.sqlserver.jdbc.spark") \
.option("url", url) \
.option("dbtable", table_name) \
.option("user", user_name) \
.option("password", password).load()
display(df)
Here is the results of displaying the dataframe.
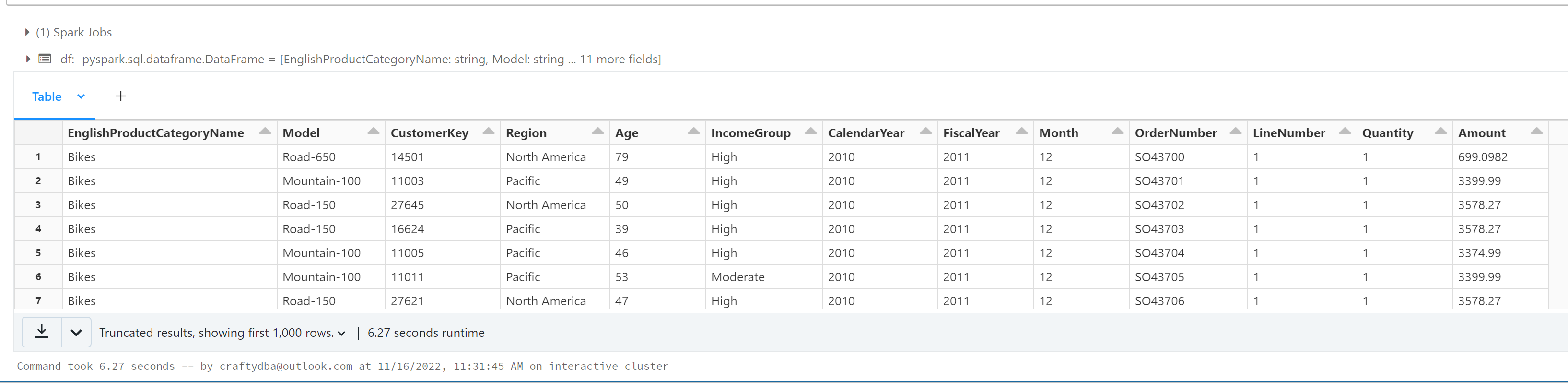
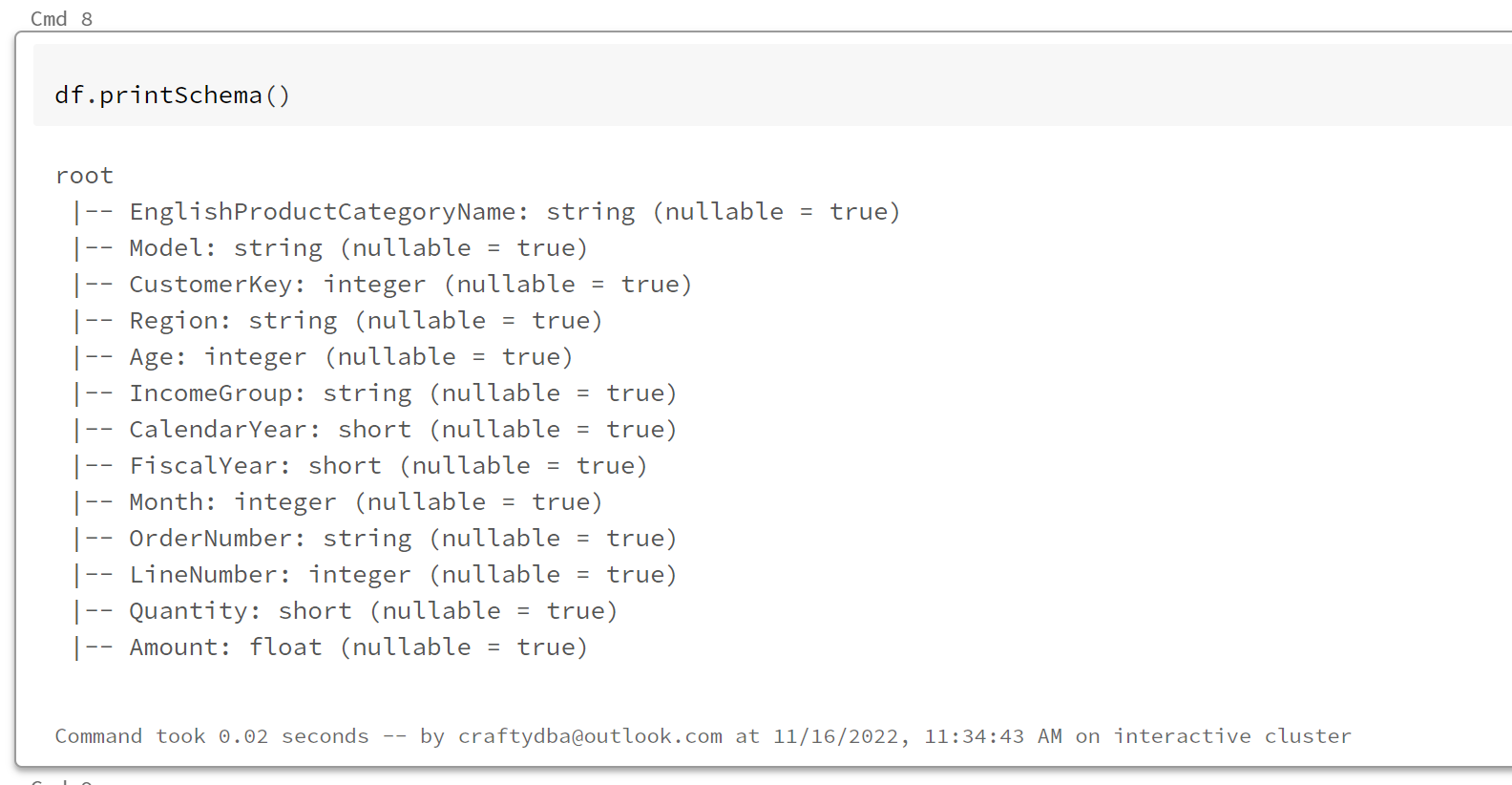
Is the data frame strictly typed? The Answer is yes since it gets the field information from SQL Server.
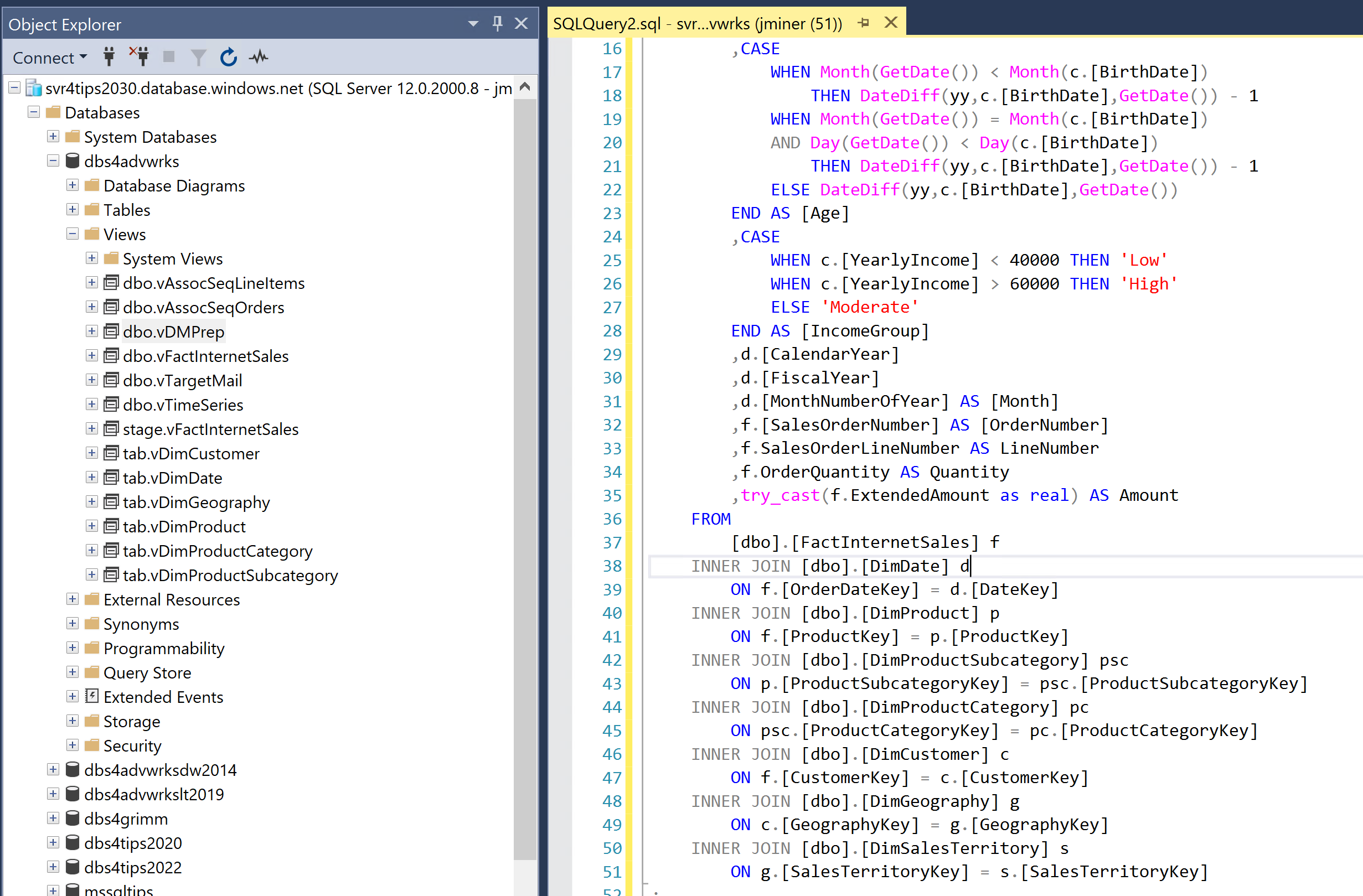
Last but not least, is the view complex? The image below shows 8 tables are joined and aggregated to get the final result for the view.
In summary, use views in the database to pre-compile your data sets for Spark. Use the JDBC driver from Microsoft to read and write from SQL Server using dataframe.
As for the stored procedure, there is a way to used the driver to execute non queries. I will have to look for the code. Stay tuned for an update or part 2.
CodePudding user response:
This is part two of the answer. There is no good way to return results from a Stored Procedure call as a dataframe.
Here is a link on the MSFT github site for this driver stating that stored procedures are not supported.