I am working on a pandas dataframe with millions of rows containing some transactions information.
Example dataframe:
df = pd.DataFrame({'ProductID': ['Afiliates','Afiliates','Afiliates','Afiliates','Afiliates','Afiliates'],
'partner': ['Amazon','Awin','Amazon','Amazon','Amazon','Amazon'],
'date': [dt.date(2022,11,1),dt.date(2022,11,5),dt.date(2022,11,1),dt.date(2022,11,10),dt.date(2022,11,15),dt.date(2022,11,1)],
'customerID' : ['01','01','01','01','02','01'],
'brand' : ['Amazon','Ponto','Amazon','Amazon','Amazon','Amazon'],
'sku':['firetv','alexa','alexa','firetv','firetv','firetv'],
'transactionID': ['51000','55000','51000','53000','54000','51000'],
'gmv' : [10,50,30,40,50,60] })
I am working on a way to aggregate some rows that are related (same transactionID), keeping all columns and structure.
I´ve tried to execute a groupby on all columns and some aggregate function over brand (list) and gmv (sum)
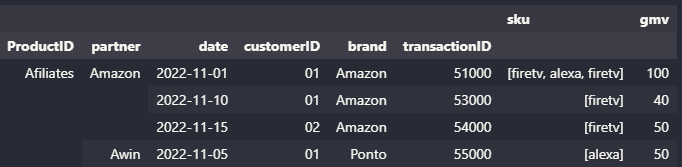
df.groupby(['ProductID','partner','date','customerID','brand','transactionID']).aggregate({'sku':list, 'gmv':'sum'})
My question is, how to a create a list of "unique" itens, as you can see, e.g., 'firetv' could appear several times on the same row after aggregation.
CodePudding user response:
You can use set() to remove duplicates, for example:
x = df.groupby(
["ProductID", "partner", "date", "customerID", "brand", "transactionID"]
).aggregate({"sku": lambda x: list(set(x)), "gmv": "sum"})
print(x)
Prints:
sku gmv
ProductID partner date customerID brand transactionID
Afiliates Amazon 2022-11-01 01 Amazon 51000 [firetv, alexa] 100
2022-11-10 01 Amazon 53000 [firetv] 40
2022-11-15 02 Amazon 54000 [firetv] 50
Awin 2022-11-05 01 Ponto 55000 [alexa] 50