I have a 2D list from which I am trying to extract the unique rows example:
list = [['16', 'jun', 'jun', '18'],
['jun', '16', 'jun', '18'],
['aug', '16', 'jun', '18'],
['aug', '16', 'jun', '18'],
['sep', '17', 'mar', '18']]
should return
desired_list = [['16', 'jun', 'jun', '18'],
['aug', '16', 'jun', '18'],
['sep', '17', 'mar', '18']]
explanation:
- So, if we compare row 1 with row 2 in list we see the items inside the two rows is same hence, I will take one of the row and store in desired_list
- row 3 and 4 in list are exactly same therefore, I'll store any one row in desired_list.
- row 5 is totally unique therefore, I'll add in desired_list.
My only target is to remove duplicate value rows(even if items inside rows have different order) and only store the unique rows.
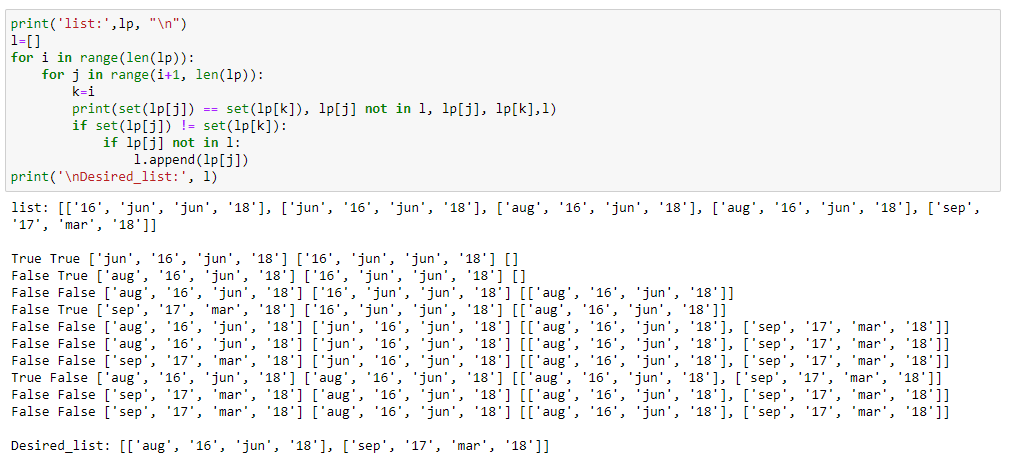
print('LP:',lp, "\n")
l=[]
for i in range(len(lp)):
for j in range(i 1, len(lp)):
k=i
print(set(lp[j]) == set(lp[k]), lp[j] not in l, lp[j], lp[k],l)
if set(lp[j]) != set(lp[k]):
if lp[j] not in l:
l.append(lp[j])
print('\n', l)
I am only half successful in achieving this. Below I am attaching the screenshot of the output so far:
CodePudding user response:
Pure pythonic solution:
res = []
for row in your_list:
sorted_row = sorted(row)
if sorted_row not in [sorted(x) for x in res]:
res.append(row)
print(res)
>>> [['16', 'jun', 'jun', '18'],
['aug', '16', 'jun', '18'],
['sep', '17', 'mar', '18']]
CodePudding user response:
#input
in_list = [['16', 'jun', 'jun', '18'],
['jun', '16', 'jun', '18'],
['aug', '16', 'jun', '18'],
['aug', '16', 'jun', '18'],
['sep', '17', 'mar', '18']]
#output
np.array(in_list)[np.sort(np.unique(np.sort(in_list), axis=0, return_index=True)[1])].tolist()
Explanation:
np.sortthe rows ofin_listin order to find the rows having the same information;- take the index from
np.uniqueto find the indices of unique (sorted) rows; np.sortthe indices to hold the starting order inin_list;- slice the list (after converting it in
np.array) with the sorted indices to only retain the unique rows; - converting the result in a list (
.tolist())