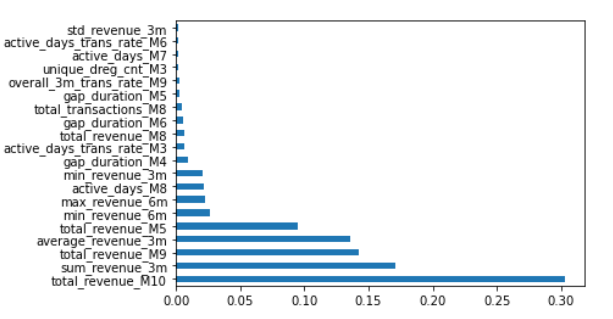
I am trying to plot the feature importance generated using random forest algorithm using the below code.
However, the largest values are shown at the bottom. But I want them to be at the top.
feat_importances = pd.Series(g_search.best_estimator_.feature_importances_, index=X_train.columns)
feat_importances.nlargest(20).plot(kind='barh')
You can see the graph below that all large values are at the bottom. But, I want them to appear on top of the graph.
Why is the output showing in reverse order?
CodePudding user response:
You can reverse your y-axis:
plt.gca().invert_yaxis()