I'm trying to clean data from an Excel file with PANDAS.
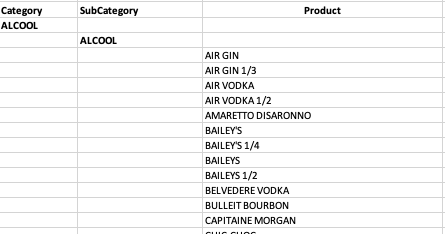
I want to fill the missing values from the category and subcategory columns.
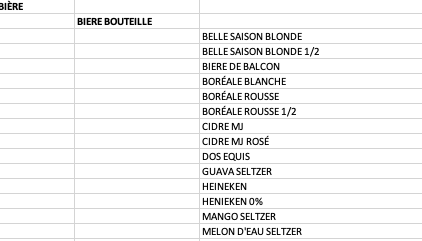
I was thinking a for loop, but I not sure how I would do that. Anyone know or have a better idea to manage this data ?
CodePudding user response:
Pandas has a handy .fillna() method that helps here. Assuming your data is stored in spreadsheet.csv, you can just use the code below. The ffill method is an abbreviation for "forward fill" - meaning that it will go down each column and fill a missing value with the value above it.
df = pd.read_csv('spreadsheet.csv')
df.fillna(method='ffill')
Alternatively, if you want to manually specify a fill value for each column, you can pass a dictionary into .fillna() using the column names for keys, and replacement for values. For example:
df.fillna({'Category': 'new category value',
'SubCategory': 'new subcategory',
'Product': "No product"})