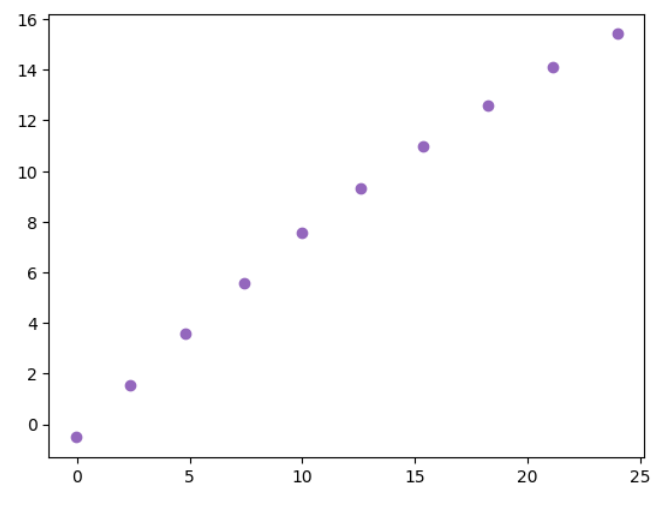
I have a dataset that consists of 5 rows that are formed like a curve. I want to separate the inner row from the other or if possible each row and store them in a separate array. Is there any way to do this, like somehow flatten the curved data and sorting it afterwards based on the x and y values?
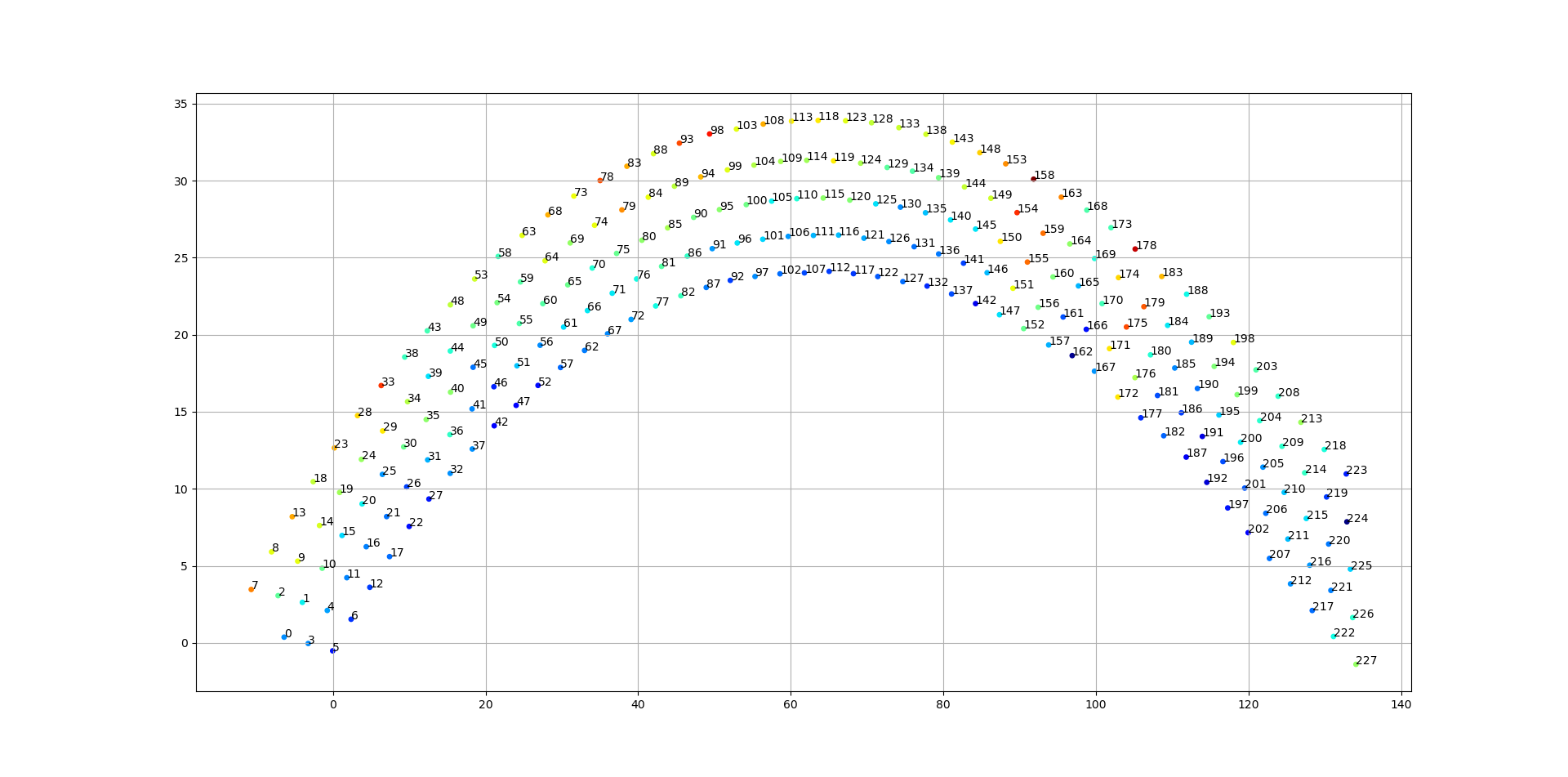
I would like to assign each row from left to right numbers from 0 to the max of the row. Right now the labels for each dot are not useful for me and I can't change the labels.
Here are the first 50 data points of my data set:
x y
0 -6.4165 0.3716
1 -4.0227 2.63
2 -7.206 3.0652
3 -3.2584 -0.0392
4 -0.7565 2.1039
5 -0.0498 -0.5159
6 2.363 1.5329
7 -10.7253 3.4654
8 -8.0621 5.9083
9 -4.6328 5.3028
10 -1.4237 4.8455
11 1.8047 4.2297
12 4.8147 3.6074
13 -5.3504 8.1889
14 -1.7743 7.6165
15 1.1783 6.9698
16 4.3471 6.2411
17 7.4067 5.5988
18 -2.6037 10.4623
19 0.8613 9.7628
20 3.8054 9.0202
21 7.023 8.1962
22 9.9776 7.5563
23 0.1733 12.6547
24 3.7137 11.9097
25 6.4672 10.9363
26 9.6489 10.1246
27 12.5674 9.3369
28 3.2124 14.7492
29 6.4983 13.7562
30 9.2606 12.7241
31 12.4003 11.878
32 15.3578 11.0027
33 6.3128 16.7014
34 9.7676 15.6557
35 12.2103 14.4967
36 15.3182 13.5166
37 18.2495 12.5836
38 9.3947 18.5506
39 12.496 17.2993
40 15.3987 16.2716
41 18.2212 15.1871
42 21.1241 14.0893
43 12.3548 20.2538
44 15.3682 18.9439
45 18.357 17.8862
46 21.0834 16.6258
47 23.9992 15.4145
48 15.3776 21.9402
49 18.3568 20.5803
50 21.1733 19.3041
CodePudding user response:
It seems that your curves have a pattern, so you could select the curve of interest using splicing. I had the offset the selection slightly to get the five curves because the first 8 points are not in the same order as the rest of the data. So the initial 8 data points are discarded. But these could be added back in afterwards if required.
import pandas as pd
import matplotlib.pyplot as plt
df = pd.DataFrame({ 'x': [-6.4165, -4.0227, -7.206, -3.2584, -0.7565, -0.0498, 2.363, -10.7253, -8.0621, -4.6328, -1.4237, 1.8047, 4.8147, -5.3504, -1.7743, 1.1783, 4.3471, 7.4067, -2.6037, 0.8613, 3.8054, 7.023, 9.9776, 0.1733, 3.7137, 6.4672, 9.6489, 12.5674, 3.2124, 6.4983, 9.2606, 12.4003, 15.3578, 6.3128, 9.7676, 12.2103, 15.3182, 18.2495, 9.3947, 12.496, 15.3987, 18.2212, 21.1241, 12.3548, 15.3682, 18.357, 21.0834, 23.9992, 15.3776, 18.3568, 21.1733],
'y': [0.3716, 2.63, 3.0652, -0.0392, 2.1039, -0.5159, 1.5329, 3.4654, 5.9083, 5.3028, 4.8455, 4.2297, 3.6074, 8.1889, 7.6165, 6.9698, 6.2411, 5.5988, 10.4623, 9.7628, 9.0202, 8.1962, 7.5563, 12.6547, 11.9097, 10.9363, 10.1246, 9.3369, 14.7492, 13.7562, 12.7241, 11.878, 11.0027, 16.7014, 15.6557, 14.4967, 13.5166, 12.5836, 18.5506, 17.2993, 16.2716, 15.1871, 14.0893, 20.2538, 18.9439, 17.8862, 16.6258, 15.4145, 21.9402, 20.5803, 19.3041]})
# Generate the 5 dataframes
df_list = [df.iloc[i 8::5, :] for i in range(5)]
# Generate the plot
fig = plt.figure()
for frame in df_list:
plt.scatter(frame['x'], frame['y'])
plt.show()
# Print the data of the innermost curve
print(df_list[4])
OUTPUT:
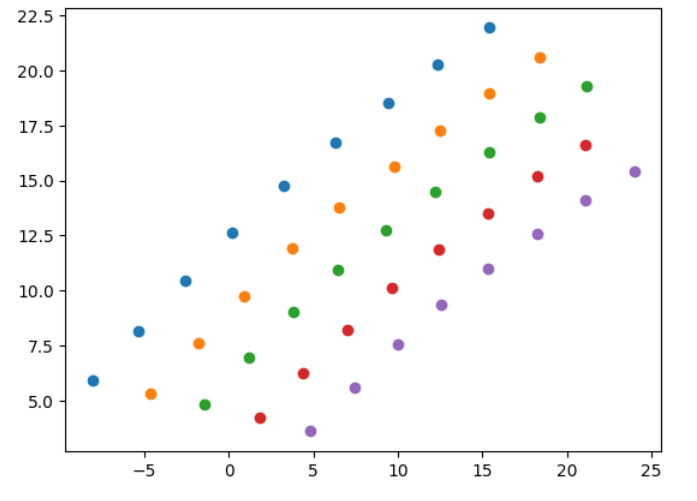
The 5th dataframe df_list[4] contains the data of the innermost plot.
x y
12 4.8147 3.6074
17 7.4067 5.5988
22 9.9776 7.5563
27 12.5674 9.3369
32 15.3578 11.0027
37 18.2495 12.5836
42 21.1241 14.0893
47 23.9992 15.4145
You can then add the missing data like this:
# Retrieve the two missing points of the inner curve
inner_curve = pd.concat([df_list[4], df[5:7]]).sort_index(ascending=True)
print(inner_curve)
# Plot the inner curve only
fig2 = plt.figure()
plt.scatter(inner_curve['x'], inner_curve['y'], color = '#9467BD')
plt.show()
OUTPUT: inner curve
x y
5 -0.0498 -0.5159
6 2.3630 1.5329
12 4.8147 3.6074
17 7.4067 5.5988
22 9.9776 7.5563
27 12.5674 9.3369
32 15.3578 11.0027
37 18.2495 12.5836
42 21.1241 14.0893
47 23.9992 15.4145
Complete Inner Curve