I made a web scrapper for parsing test cases of Atcoder contest. It works well if the contest is already finished but gives an error for an ongoing contest. The error arises when accessing the rows of the table HTML element. I am positive that the table exists but for some reason, the script returns undefined for an ongoing contest.
Error:
Error: Evaluation failed: TypeError: Cannot read properties of undefined (reading 'rows')
at pptr://__puppeteer_evaluation_script__:3:32
at ExecutionContext._ExecutionContext_evaluate (/mnt/d/c /node_modules/puppeteer-core/lib/cjs/puppeteer/common/ExecutionContext.js:229:15)
at process.processTicksAndRejections (node:internal/process/task_queues:95:5)
at async ExecutionContext.evaluate (/mnt/d/c /node_modules/puppeteer-core/lib/cjs/puppeteer/common/ExecutionContext.js:107:16)
at async scrapeSite (/mnt/d/c /codeforces/atcoder.js:57:33)
Here is my Scrapper: atcoder.js:
const puppeteer = require("puppeteer");
const fs = require("fs");
const contest_id = process.argv[2];
async function scrapeProblem(problem_letter) {
const url = `https://atcoder.jp/contests/${contest_id}/tasks/${contest_id}_${problem_letter.toLowerCase()}`;
console.log(url);
try {
const browser = await puppeteer.launch();
const page = await browser.newPage();
await page.goto(url, { waitUntil: "networkidle0" });
const samples_scraped = await page.evaluate(() => {
const samples = document.querySelectorAll("pre");
const scraped = Array.from(samples).filter((child) => {
return child.id !== "";
});
let num_scraped = scraped.length;
// The elements were repeated twice, so remove the extra elements
for (let i = 0; i < num_scraped / 2; i ) scraped.pop();
return scraped.map((ele) => ele.innerText);
// return Array.from(samples).map((child) => child.innerText);
});
let id = 1;
// Now we need to store the samples in text format
samples_scraped.map((ele, idx) => {
if (idx % 2 == 0) {
// Input
fs.writeFile(`${problem_letter}-${id}.in`, ele, (err) => {
if (err) throw err;
});
} else {
// Output
fs.writeFile(`${problem_letter}-${id}.out`, ele, (err) => {
if (err) throw err;
});
id ;
}
return ele;
});
await browser.close();
} catch (e) {
console.log(e);
}
}
async function scrapeSite() {
const url = `https://atcoder.jp/contests/${contest_id}/tasks`;
console.log(url);
try {
const browser = await puppeteer.launch();
const page = await browser.newPage();
await page.goto(url, { waitUntil: "networkidle0" });
// Returns all the problem letters
const problem_letters = await page.evaluate(() => {
const table = document.querySelectorAll("table")[0];
const rows = table.rows.length;
const letters = [];
for (let i = 1; i < rows; i ) {
letters.push(table.rows[i].cells[0].innerText);
}
return letters;
});
console.log(problem_letters);
for (problem_letter of problem_letters) {
scrapeProblem(problem_letter);
}
await browser.close();
} catch (e) {
console.log(e);
}
}
scrapeSite();
The scrapeProblem(problem_letter) is a helper function to scrape the test cases for the given problem letter. It then stores the test cases to the user's file system using fs module.
The scrapeSite() function first parses the homepage for the number of problems and the problem letter associated with each problem. It then calls the scrapeProblem(problem_letter) helper function to parse the required web site for test cases.
To run the script: node scrapper.js abc280
Update: I tried it in a new contest and again got the same error. This time I took a screenshot using Puppeteer and found out the problem. I am getting permission denied if I try to accesss the site without logging in for an ongoing contest.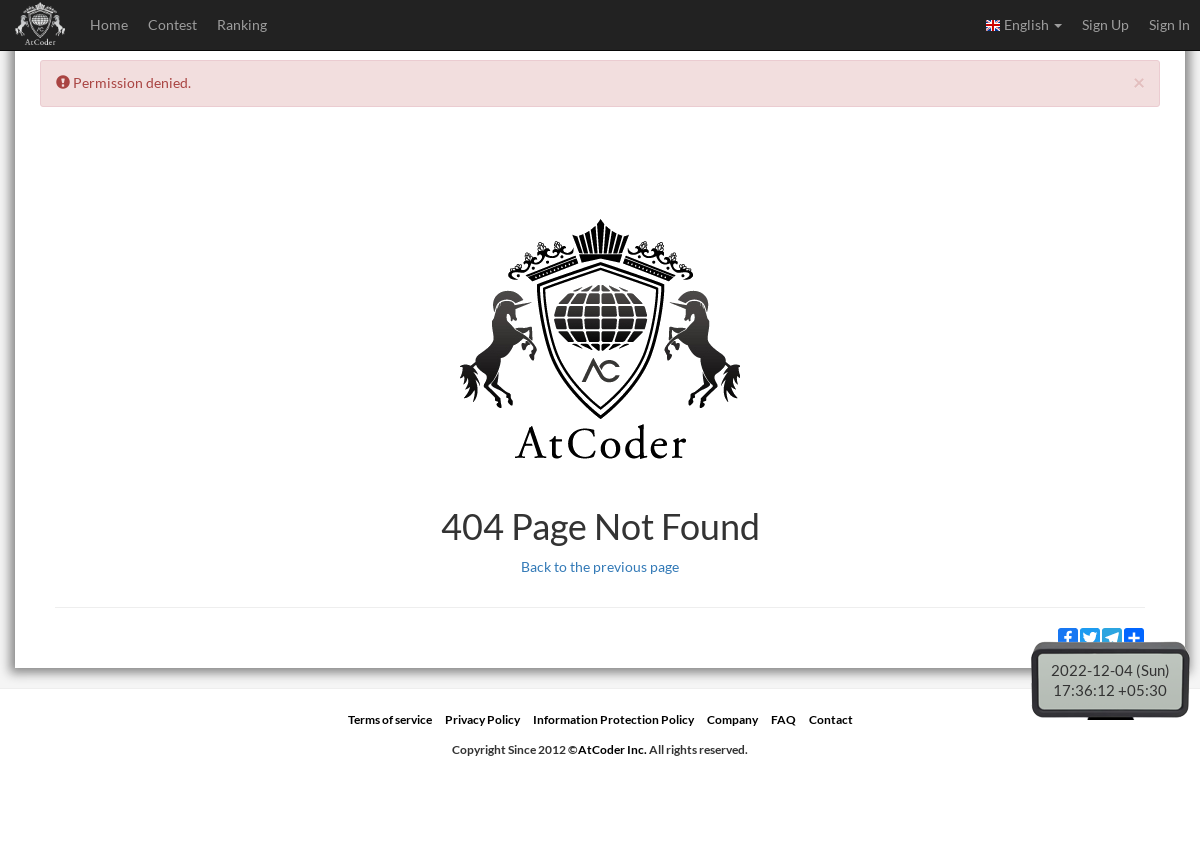
CodePudding user response:
The problem was the site requires us to login and only then we can see the problem statements of an ongoing contest. So I added a function which will first login to the site and then it will proceed to parse the test cases.
Updated code:
const puppeteer = require("puppeteer");
const fs = require("fs");
require('dotenv').config();
const contest_id = process.argv[2];
async function login(browser, page) {
const url = `https://atcoder.jp/login?continue=https://atcoder.jp/`;
console.log("Logging in..", url);
try {
await page.goto(url, { waitUntil: "networkidle0" });
await page.type('#username', process.env.USERNAME);
await page.type("#password", process.env.PASSWORD);
await page.click("#submit");
} catch (e) {
console.log("Login failed...");
console.log(e);
}
}
async function scrapeProblem(browser, Problem) {
const url = Problem.Url;
console.log(url);
try {
// const browser = await puppeteer.launch();
const page = await browser.newPage();
// await login(browser, page);
await page.goto(url, { waitUntil: "networkidle0" });
const samples_scraped = await page.evaluate(() => {
const samples = document.querySelectorAll("pre");
const scraped = Array.from(samples).filter((child) => {
return child.id !== "";
});
let num_scraped = scraped.length;
// The elements were repeated twice, so remove the extra elements
for (let i = 0; i < num_scraped / 2; i ) scraped.pop();
return scraped.map((ele) => ele.innerText);
// return Array.from(samples).map((child) => child.innerText);
});
let id = 1;
// Now we need to store the samples in text format
samples_scraped.map((ele, idx) => {
if (idx % 2 == 0) {
// Input
fs.writeFile(`${Problem.Problem_letter}-${id}.in`, ele, (err) => {
if (err) throw err;
});
} else {
// Output
fs.writeFile(`${Problem.Problem_letter}-${id}.out`, ele, (err) => {
if (err) throw err;
});
id ;
}
return ele;
});
// await browser.close();
} catch (e) {
console.log(e);
}
}
async function scrapeSite() {
const url = `https://atcoder.jp/contests/${contest_id}/tasks`;
console.log(url);
try {
const browser = await puppeteer.launch();
const page = await browser.newPage();
await login(browser, page);
await page.goto(url, { waitUntil: "networkidle0" });
// await page.screenshot({ path: "./screenshot.png", fullPage: true});
// Returns all the problem letters
const problems = await page.evaluate(() => {
const table = document.querySelectorAll("table")[0];
const rows = table.rows.length;
const letters = [];
for (let i = 1; i < rows; i ) {
letters.push({Problem_letter: table.rows[i].cells[0].innerText, Url: table.rows[i].cells[0].firstChild.href });
}
return letters;
});
console.log(problems);
const promises = []
for (problem of problems) {
promises.push(scrapeProblem(browser, problem));
}
await Promise.all(promises); // All the promises must be resolved before closing the browser
await browser.close();
} catch (e) {
console.log(e);
}
}
scrapeSite();