I have the following dataframe:
row issue_status market_phase trade_type
0 20 0
1 10 0
2 20 0
3 10 0
4 10 0
5 10 0
I would like to map the first instance of (issue_status == 10 & market_phase == 0) to OPENING_AUCTION.
And any subsequent occurrences of the above, I would like to map it to CONTINUOUS_AUCTION.
So I would like the dataframe to look like this:
row issue_status market_phase trade_type
0 20 0 ->
1 10 0 -> OPENING_AUCTION
2 20 0 ->
3 10 0 -> CONTINUOUS_TRADING
4 10 0 -> CONTINUOUS_TRADING
5 10 0 -> CONTINUOUS_TRADING
Here is my code:
market_info_df.loc[market_info_df['issue_status' == '10', 'market_phase' == '0'].iloc[0]] = MARKET_STATES.OPENING_AUCTION
market_info_df.loc[market_info_df['issue_status' == '10', 'market_phase' == '0']].iloc[1:] = MARKET_STATES.INTRADAY_AUCTION
When I run the above I get KeyError: (False, False, False)
Note that I need to use iloc in the code- any ideas how I would achieve the above?
CodePudding user response:
Disregarding performances, you can iterate through your dataframe:
import pandas as pd
df = pd.DataFrame({'row': [0, 1, 2, 3, 4, 5],
'issue_status': [20, 10, 20, 10, 10, 10],
'market_phase': [0, 0, 0, 0, 0, 0],
'trade_type': None},)
trade_type_column = df.columns.get_loc("trade_type") # so you can use iloc
already_done = False
for row in range(len(df)):
if df.loc[row, 'issue_status'] == 10 and df.loc[row, 'market_phase'] == 0:
if not already_done:
df.iloc[row, trade_type_column] = 'OPENING_AUCTION'
already_done = True
else:
df.iloc[row, trade_type_column] = 'CONTINUOUS_TRADING'
This is what I get: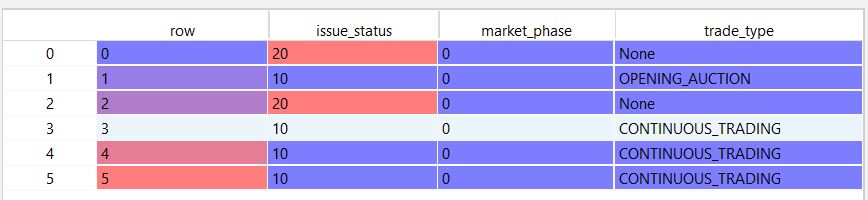
CodePudding user response:
This might not be the most efficient solution, but it's possible using df.loc and np.argmax.
import pandas as pd
df = pd.DataFrame({"row": [0,1,2,3,4,5],
"issue_status": [20,10,20,10,10,10],
"market_phase": [0,0,0,0,0,0],
"trade_type": [""] * 6})
# First set the trade_type column for all rows where the condition matches to `CONTINUOUS_TRADING`
df.loc[(df.issue_status.values == 10) & (df.market_phase.values == 0), 'trade_type'] = 'CONTINUOUS_TRADING'
# Set trade_type for first occurrence of condition to "OPENING_AUCTION"
df.loc[((df.issue_status.values == 10) & (df.market_phase.values == 0)).argmax(), 'trade_type'] = 'OPENING_AUCTION'
print(df)
Output:
row issue_status market_phase trade_type
0 0 20 0
1 1 10 0 OPENING_AUCTION
2 2 20 0
3 3 10 0 CONTINUOUS_TRADING
4 4 10 0 CONTINUOUS_TRADING
5 5 10 0 CONTINUOUS_TRADING
CodePudding user response:
Identify the rows where issue_status is 10 and market_pahase is 0 then identify the duplicate rows.. now using this information along with loc to fill the corresponding values in the trade_type column
cols = ['issue_status', 'market_phase']
m1 = df[cols].eq([10, 0]).all(1)
m2 = df[cols].duplicated()
df.loc[m1 & ~m2, 'trade_type'] = 'OPENING_AUCTION'
df.loc[m1 & m2, 'trade_type'] = 'CONTINUOUS_TRADING'
Result
row issue_status market_phase trade_type
0 0 20 0 NaN
1 1 10 0 OPENING_AUCTION
2 2 20 0 NaN
3 3 10 0 CONTINUOUS_TRADING
4 4 10 0 CONTINUOUS_TRADING
5 5 10 0 CONTINUOUS_TRADING