I am trying to scrape some information from a webpage using Selenium. In <span id='text'>, I want to extract the id value (text) and in the same div I want to extract <p> element.
here is what I have tried:
import requests
from bs4 import BeautifulSoup
# Send an HTTP request to the website and retrieve the HTML code of the webpage
response = requests.get('https://www.osha.gov/laws-regs/regulations/standardnumber/1926/1926.451#1926.451(a)(6)')
html = response.text
# Parse the HTML code using Beautiful Soup to extract the desired information
soup = BeautifulSoup(html, 'html.parser')
# find all <a> elements on the page with name attribute
links = soup.find_all('a', attrs={'name': True})
print(links)
linq = []
for link in links:
#print(link['name'])
linq.append(link['name'])
information = soup.find_all('p') # find all <p> elements on the page
# This is how I did it
with open('osha.txt', 'w') as f:
for i in range(len(linq)):
f.write(linq[i])
f.write('\n')
f.write(infoo[i])
f.write('\n')
f.write('-' * 50)
f.write('\n')
Below is the HTML code.
What I want is to save this in a separate text file is this information:
1926.451(a)
Capacity
<div >
<div >
<span id="1926.451(a)">
<a href="/laws-regs/interlinking/standards/1926.451(a)" name="1926.451(a)">
1926.451(a)
</a>
</span>
<div >
<p>"Capacity"</p>
</div>
</div>
</div>
CodePudding user response:
Some of the a tag and paragraph you might missing on the page. Use try except block to handle that.
Use css selector to get the parent node and then get respective child nodes. user dataframe to store the value and export it to csv file.
import pandas as pd
import csv
import requests
from bs4 import BeautifulSoup
# Send an HTTP request to the website and retrieve the HTML code of the webpage
response = requests.get('https://www.osha.gov/laws-regs/regulations/standardnumber/1926/1926.451#1926.451(a)(6)')
html = response.text
code=[]
para=[]
# Parse the HTML code using Beautiful Soup to extract the desired information
soup = BeautifulSoup(html, 'html.parser')
for item in soup.select(".field.field--name-field-reg-standard-number .field--item"):
try:
code.append(item.find("a").text.strip())
except:
code.append(item.find("span").text.strip())
try:
para.append(item.find("p").text.strip())
except:
para.append("Nan")
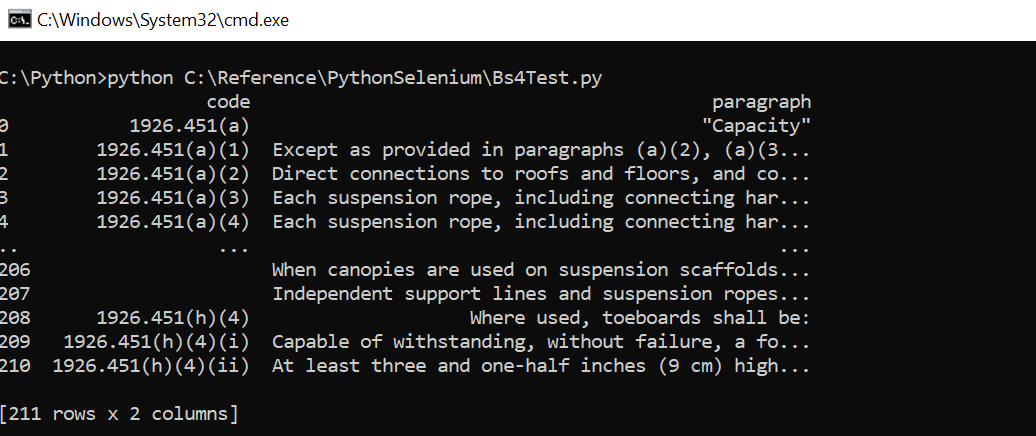
df=pd.DataFrame({"code" : code, "paragraph" : para})
print(df)
df.to_csv("path/to/filenme")
Output: