I am working with the R programming language.
I have a dataset that looks something like this:
x = c("GROUP", "A", "B", "C")
date_1 = c("CLASS 1", 20, 60, 82)
date_1_1 = c("CLASS 2", 37, 22, 8)
date_2 = c("CLASS 1", 15,100,76)
date_2_1 = c("CLASS 2", 84, 18,88)
my_data = data.frame(x, date_1, date_1_1, date_2, date_2_1)
x date_1 date_1_1 date_2 date_2_1
1 GROUP CLASS 1 CLASS 2 CLASS 1 CLASS 2
2 A 20 37 15 84
3 B 60 22 100 18
4 C 82 8 76 88
I am trying to restructure the data so it looks like this:
- note : in the real excel data, date_1 is the same date as date_1_1 and date_2 is the same as date_2_1 ... R wont accept the same names, so I called them differently
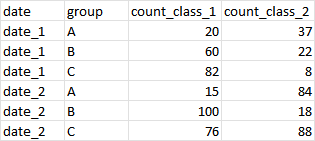
Currently, I am manually doing this in Excel using different "tranpose" functions - but I am wondering if there is a way to do this in R (possibly using the DPLYR library).
I have been trying to read different tutorial websites online (Pivoting), but so far nothing seems to match the problem I am trying to work on.
Can someone please show me how to do this?
Thanks!
CodePudding user response:
Made assumptions about your data because of the duplicate column names. For example, if the Column header pattern is CLASS_ClassNum_Date
df<-data.frame(GROUP = c("A", "B", "C"),
CLASS_1_1 = c(20, 60, 82),
CLASS_2_1 = c(37, 22, 8),
CLASS_1_2 = c(15,100,76),
CLASS_2_2 = c(84, 18,88))
library(tidyr)
pivot_longer(df, -GROUP,
names_pattern = "(CLASS_.*)_(.*)",
names_to = c(".value", "Date"))
GROUP Date CLASS_1 CLASS_2 <chr> <chr> <dbl> <dbl> 1 A 1 20 37 2 A 2 15 84 3 B 1 60 22 4 B 2 100 18 5 C 1 82 8 6 C 2 76 88
Edit: Substantially improved pivot_longer by using names_pattern= correctly
CodePudding user response:
There are lots of ways to achieve your desired outcome, but I don't believe there is an 'easy'/'simple' way. Here is one potential solution:
library(tidyverse)
library(vctrs)
x = c("GROUP", "A", "B", "C")
date_1 = c("CLASS 1", 20, 60, 82)
date_1_1 = c("CLASS 2", 37, 22, 8)
date_2 = c("CLASS 1", 15,100,76)
date_2_1 = c("CLASS 2", 84, 18,88)
my_data = data.frame(x, date_1, date_1_1, date_2, date_2_1)
# Combine column names with the names in the first row
colnames(my_data) <- paste(my_data[1,], colnames(my_data), sep = "-")
my_data %>%
filter(`GROUP-x` != "GROUP") %>% # remove first row (info now in column names)
pivot_longer(everything(), # pivot the data
names_to = c(".value", "Date"),
names_sep = "-") %>%
mutate(GROUP = vec_fill_missing(GROUP, # fill NAs in GROUP introduced by pivoting
direction = "downup")) %>%
filter(Date != "x") %>% # remove "unneeded" rows
mutate(`CLASS 2` = vec_fill_missing(`CLASS 2`, # fill NAs again
direction = "downup")) %>%
na.omit() %>% # remove any remaining NAs
mutate(across(starts_with("CLASS"), ~as.numeric(.x)),
Date = str_extract(Date, "\\d ")) %>%
rename("date" = "Date", # rename the columns
"group" = "GROUP",
"count_class_1" = `CLASS 1`,
"count_class_2" = `CLASS 2`) %>%
arrange(date) # arrange by "date" to get your desired output
#> # A tibble: 6 × 4
#> date group count_class_1 count_class_2
#> <chr> <chr> <dbl> <dbl>
#> 1 1 A 20 37
#> 2 1 B 60 84
#> 3 1 C 82 18
#> 4 2 A 15 37
#> 5 2 B 100 22
#> 6 2 C 76 8
Created on 2022-12-09 with reprex v2.0.2