I have a website i want to scrape but the information am looking for is contained in an "li" tag. This "li" tag has no class or id. Also all the "li" tags are contained in an "ul" tag without class or id. There are about 25 "li" tags contained in one "ul". How do i iterate this "li" tag to get all the informations contained in the 25 "li" tags. Meanwhile I want to do this with selenium
Pictorial representation
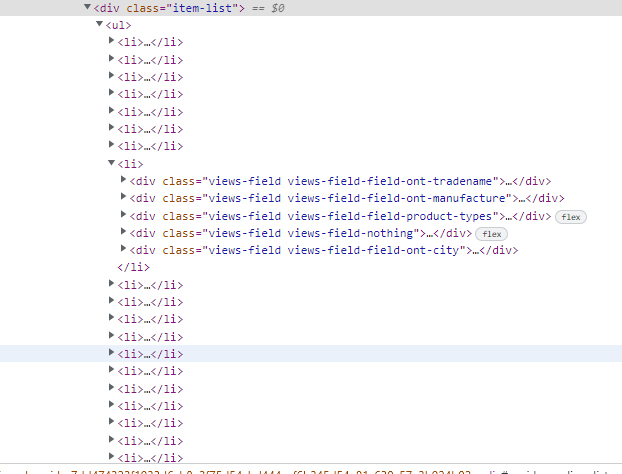
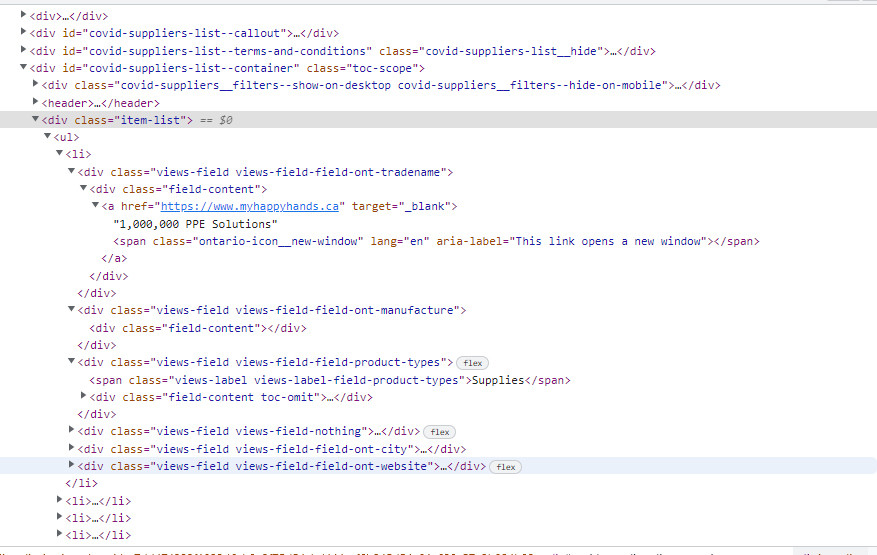
I want to extract the text elements contained in the "div". For example first "div" has '1,000,000 PPE Solutions'. I want to extract such text for all the "li" tags.
CodePudding user response:
Try below xpath in selenium
//div[contains(@class, 'tradename')]/..
CodePudding user response:
You can try this:
This will list all the li tags:
XPATH:
.//div[@class='item-list']/ul/li
CSS_SELECTOR:
.item-list ul li
Also, within the li tag which information do you want to access?, for that , you need to post the URL or the complete HTML source.
CodePudding user response:
from selenium.webdriver import webdriver , keys
driver = webdriver.chrome()
driver.get("https://your_target_site.com")
my_li_elements = driver.find_element_by_tag_name('li')
my_li_elements_text = my_li_elements.text
now you can use any loops to iterate
i hope it will help you