import pandas as pd
df = pd.DataFrame({'cost_m1': [10, 11, 140], 'cost_m2': [130, 90, 110], 'cost_m3': [80, 110, 120],
'prob_m1': [0.1, 0.11, 0.25], 'prob_m2':[0.13, 0.19, 0.19], 'prob_m3':[0.21, 0.11, 0.14] })
df = df.reset_index() # make sure indexes pair with number of rows
I have got the dataframe above where costs and their corresponding probabilities are given. What I want is the following output. Any help would be greatly appreciated.
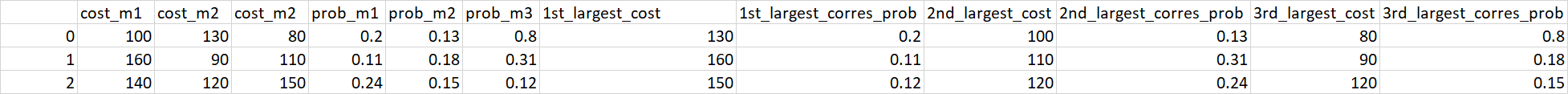
CodePudding user response:
You can first create an intermediate DataFrame with a MultiIndex, then perform indexing lookup using the sorted order of "Cost":
import numpy as np
df2 = (df
.drop(columns='index', errors='ignore')
.pipe(lambda d: d.set_axis(d.columns.str.split('_', expand=True), axis=1))
)
idx = (np.arange(len(df2))[:, None], np.argsort(-df2['cost']))
out = df.join(pd.concat([
pd.DataFrame(df2['cost'].to_numpy()[idx], index=df.index).add_prefix('cost_'),
pd.DataFrame(df2['prob'].to_numpy()[idx], index=df.index).add_prefix('prob_')
], axis=1)
)
print(out)
Output:
index cost_m1 cost_m2 cost_m3 prob_m1 prob_m2 prob_m3 cost_0 cost_1 cost_2 prob_0 prob_1 prob_2
0 0 10 130 80 0.10 0.13 0.21 130 80 10 0.13 0.21 0.10
1 1 11 90 110 0.11 0.19 0.11 110 90 11 0.11 0.19 0.11
2 2 140 110 120 0.25 0.19 0.14 140 120 110 0.25 0.14 0.19
CodePudding user response:
Here's a way to do it:
df1 = ( pd.DataFrame(
[sorted(((df.loc[i,f'cost_m{j}'], df.loc[i,f'prob_m{j}']) for j in range(1,4)), reverse=True)
for i in range(len(df))]) )
df1 = ( pd.DataFrame(
[df1.iloc[i,].explode().to_numpy() for i in range(len(df1))],
columns=pd.Series([(f'{nth}_largest_cost', f'{nth}_largest_corres_prob') for nth in ('1st','2nd','3rd')]).explode()) )
df = pd.concat([df.drop(columns='index'), df1], axis=1)
Output:
cost_m1 cost_m2 cost_m3 prob_m1 prob_m2 prob_m3 1st_largest_cost 1st_largest_corres_prob 2nd_largest_cost 2nd_largest_corres_prob 3rd_largest_cost 3rd_largest_corres_prob
0 10 130 80 0.10 0.13 0.21 130 0.13 80 0.21 10 0.10
1 11 90 110 0.11 0.19 0.11 110 0.11 90 0.19 11 0.11
2 140 110 120 0.25 0.19 0.14 140 0.25 120 0.14 110 0.19
Explanation:
- create a new dataframe that pairs cost and prob for m1, m2 and m3 and sorts in reverse
- create another dataframe using a list of exploded rows (to get interleaved cost/prob columns) from the previous dataframe together with the desired new column labels, and concat it to the right of the original dataframe with the column named
indexdropped.