There is a lottery game here in Brazil that at the end of the year (12/31/2022) pays a higher amount, I did the webscrap and captured all the games and included them in the dataframe.
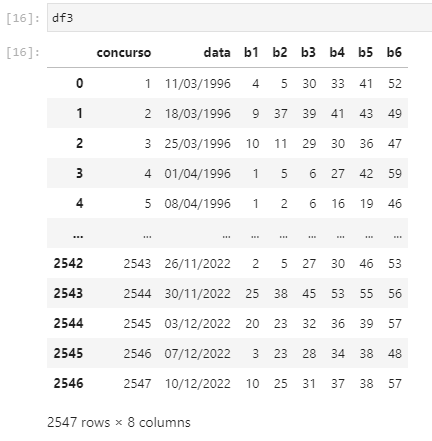
Now I want to get only the games from the 12/31st of each year that had these games to use them as a test in a neural network prediction, but when including in a new dataframe with only these games, each data in the column is as a list as shown below.
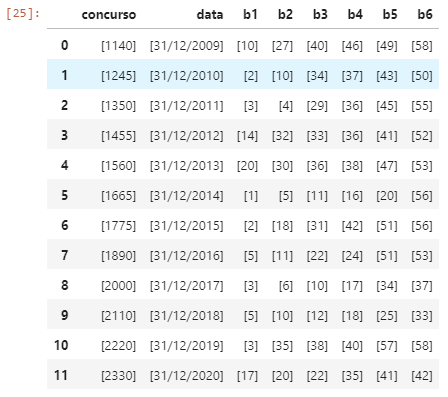
I'm still learning Pandas and the code below that I used seems a little complicated, it must be simpler, because I still don't know all the properties of pandas.
df_mega_virada = pd.DataFrame(columns=['concurso','data', 'b1', 'b2', 'b3', 'b4', 'b5', 'b6'])
datas = ['31/12/2009','31/12/2010','31/12/2011','31/12/2012','31/12/2013','31/12/2014',
'31/12/2015','31/12/2016','31/12/2017','31/12/2018','31/12/2019','31/12/2020']
for x, y in enumerate(datas):
df_mega_virada.loc[x] = df3.query(f"data == '{y}'").concurso.values,df3.query(f"data == '{y}'").data.values,df3.query(f"data == '{y}'").b1.values, df3.query(f"data == '{y}'").b2.values,df3.query(f"data == '{y}'").b3.values,df3.query(f"data == '{y}'").b4.values,df3.query(f"data == '{y}'").b5.values,df3.query(f"data == '{y}'").b6.values
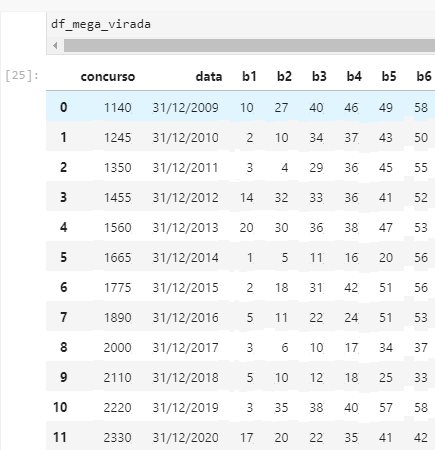
What I hope:
The link to .csv file: File csv
CodePudding user response:
I would recommend the following logic to perform the filter you are looking for:
- Create a separate series of the month and a separate series for the day of month.
- Filter rows by month == 12 and day == 31 in the dataframe.
month_series = df3["data"].dt.month
day_of_month_series = df3["data"].dt.day
df3_clean = df3[
(month_series == 12) &
(day_of_month_series == 31)
]