I am unable to convert the data retrieved with bs4 into a meaningful csv file. It only takes the last set of data from what is actually retrieved.
#Beautiful soup or BS4 is a package I will be using to allow me to parse the HTML data which I will be retrieving from a website.
#parsing is te conversion of codes from machine language into a code which humans can understand and allow it to be structured.
#(Converting data from one format to another) with BS4
from bs4 import BeautifulSoup
#requests is an HTTP Library which allows me to send requests to websites the retrieve date using Python. This is helpful as
#The website is writtin in a different language so it allows me to retrieve what I want and read it as well.
import requests
#import writer
url= "https://myanimelist.net/anime/season"
#requesting to get data using 'requests' and gain acess as well.
#hadve to check the response before moving forward to ensure there is no problem retrieving data.
page= requests.get(url)
#print(page)
#<Response [200]> response was "200" meaning "Successful responses"
soup = BeautifulSoup(page.content, 'html.parser')
#here i retrieve my
#for this to identify the html code and determine what we will be producing(retrieveing data) for each item on the page we had to
#find the parent category which contains all the info we need to make our data categories.
lists = soup.select("[data-genre]")
#we add _ after class to make class_ because without the underscore the program identifies it as a python class
# when really it is more of a cs class
all_data = []
#must create loop to find titles seperate as there are alot that will come up
for list in lists:
#identify and find class which includes the title of the shows, show ratings, members watching, and episodes
#added .text.replace in order to get rid of the|n spacing which was in html format
title= list.find("a", class_="link-title").text.replace("\n", "")
rating= list.find("div", class_="score").text.replace("\n", "")
members= list.find("div", class_="scormem-item member").text.replace("\n", "")
release_date= list.find("span", class_="item").text.replace("\n", "")
all_data.append(
[title.strip(), rating.strip(), members.strip(), release_date.strip()]
)
print(*all_data, sep="\n")
#testing for errors and makins sure locations are correct to withdraw/request the data
#this allows us to create and close a csv file. using 'w' to allow editing
from csv import writer
#defining the website which I will be retrieving my code
#organizing chart
header=['Title', 'Show Rating', 'Members', 'Release Date']
info= [title.strip(), rating.strip(), members.strip(), release_date.strip()]
with open('shows.csv', 'w', encoding='utf8', newline='')as f:
#will write onto our file 'f'
writing = writer(f)
#use our writer to write a row in file
writing.writerow(header)
writing.writerow(info)
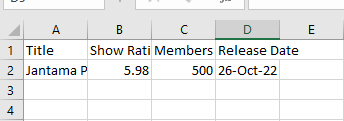
I tried to change definition of list but to no avail. This is currently what I get. Even though it should be much longer.
CodePudding user response:
Instead of writing just the last line with
writing.writerow(info)
you need to write all of the lines:
writing.writerows(all_data)